ELK Stack چیست ؟
ELK Stack (مخفف Elasticsearch + Logstash + Kibana) یک پنل متنباز قدرتمند و محبوب برای مدیریت، جمعآوری، پردازش و تجزیه و تحلیل لاگ هاست. این ابزار به سازمانها اجازه میدهد تا حجم عظیمی از دادههای لاگ را از منابع مختلف جمعآوری کرده، آنها را به صورت ساختیافته ذخیره کنند و با استفاده از ابزارهای قدرتمند جستجو و تجسم، به نتایج ارزشمندی دست یابند.
در زیرساخت های پیچیده IT امروزی، مدیریت و تحلیل لاگ ها برای حفظ سلامت سیستم، رفع مشکلات و تضمین امنیت بسیار مهم است. Elastic Stack امکان ایندکس کردن میلیونها رکورد در کوتاهترین زمان ممکن را به شما میدهد که این باعث صرفه جویی در سرعت پردازش لاگ های جمع اوری شده از منابع مختلف می شود.
چرا ELK Stack برای مدیریت لاگها انتخاب ایده آلی است؟
دلایل بسیاری وجود دارد که این استک را به انتخابی بی نظیر برای سازمانها تبدیل میکند:
۱. جمعآوری متمرکز لاگ
- تسهیل تحلیل: با جمعآوری لاگهای مختلف از منابع متنوع (سرورها، اپلیکیشنها، دستگاههای شبکه) در یک مکان واحد، تحلیل جامعتر و سریعتری امکانپذیر میشود.
- کاهش پیچیدگی: به جای مدیریت جداگانه لاگهای هر سیستم، با یک ابزار واحد میتوانید به تمام دادههای لاگ دسترسی داشته باشید.
۲. تحلیل به محض تولید لاگ ها
- شناسایی سریع مشکلات: Elasticsearch با قابلیت ایندکسسازی سریع، امکان جستجو و تحلیل تقریباً به محض تولید آنها را فراهم میکند.
- پاسخگویی سریعتر: مشکلات و تهدیدات امنیتی را میتوان به سرعت شناسایی و برطرف کرد.
۳. قابلیت مقیاسپذیری
- رشد همراه با کسبوکار: ELK Stack به راحتی با افزایش حجم دادهها و تعداد منابع تولیدکننده لاگ قابل مقیاسپذیری است.
- پشتیبانی از محیطهای بزرگ: برای سازمانهای بزرگ با زیرساختهای پیچیده، ELK Stack یک انتخاب ایدهآل است.
۴. جستجو و تحلیل قدرتمند
- پرسوجوهای پیچیده: Elasticsearch از زبان پرسوجوی قدرتمندی برخوردار است که به شما امکان میدهد جستجوهای پیچیده و سفارشی را روی دادههای لاگ انجام دهید.
- کشف الگوها: با استفاده از قابلیتهای تحلیل Elasticsearch میتوانید الگوها، روندها و همبستگیهای پنهان در دادهها را کشف کنید.
۵. بصریسازی جذاب
- درک بهتر دادهها: Kibana با ارائه داشبوردهای تعاملی، نمودارها و گرافها، به شما کمک میکند تا دادههای لاگ را به صورت تصویری مانیتور کنید.
- تصمیمگیری مبتنی بر داده: با تجسم دادهها، میتوانید تصمیمات بهتری در مورد بهبود عملکرد سیستم، رفع مشکلات و افزایش امنیت بگیرید.
۶. متنباز و انعطافپذیر
- هزینه کم: ELK Stack یک نرمافزار متنباز است و هزینههای لایسنس ندارد.
- سفارشیسازی: میتوانید ELK Stack را مطابق با نیازهای خاص سازمان خود سفارشیسازی کنید.
۷. جامعه بزرگ و فعال
- پشتیبانی قوی: یک جامعه بزرگ از توسعهدهندگان و کاربران ELK Stack وجود دارد که به شما در حل مشکلات و یادگیری بیشتر کمک میکنند.
- بهروزرسانیهای مداوم: ELK Stack به طور مداوم توسعه مییابد و ویژگیهای جدیدی به آن اضافه میشود.
آیا میخواهید در مورد یک جنبه خاص از ELK Stack بیشتر بدانید؟
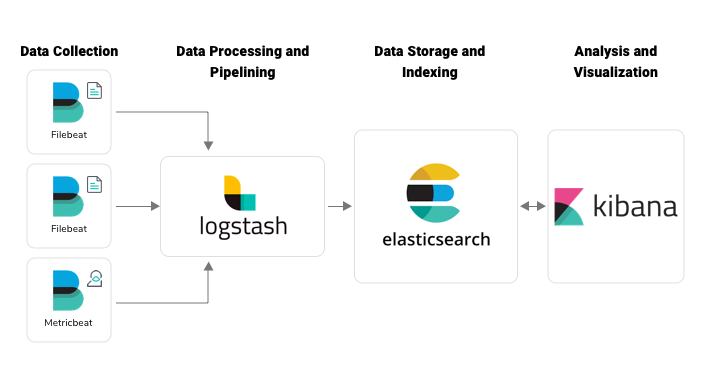
درک ELK Stack
ELK Stack مجموعهای از ابزارهای متنباز است که با هم برای جمعآوری، پردازش و تحلیل دادههای لاگ کار میکنند. بیایید هر جزء را بررسی کنیم:
- Elasticsearch: قلب این پشته، Elasticsearch یک موتور جستجو و تحلیل توزیعشده و RESTful است که قادر به ذخیره و جستجوی حجم عظیمی از دادهها در زمان واقعی است. این ابزار دادههای لاگ را برای بازیابی و تحلیل سریع ایندکس میکند. این موتور جستجو در صنایع مختلفی از جمله تجارت الکترونیک، تحلیل لاگ، IoT و تحلیل دادههای بزرگ کاربرد دارد و به عنوان یکی از محبوبترین ابزارهای جستجو در جهان شناخته میشود.
- Logstash: یک پلتفرم متنوع برای پردازش داده، Logstash دادهها را از منابع مختلف جمعآوری میکند، آن را پردازش میکند (پارس کردن (Log Parsing)، فیلتر کردن، غنیسازی) و به Elasticsearch ارسال میکند. این ابزار به عنوان یک مرکز اصلی برای جمعآوری و تبدیل لاگ عمل میکند.
- Kibana: لایه تصویر سازی، Kibana یک رابط کاربری دوستانه برای کاوش، جستجو و تجسم دادههای ذخیره شده در Elasticsearch ارائه میدهد. این ابزار داشبوردها، نمودارها و گرافها را برای تحلیل عمیق ارائه میدهد.
پیادهسازی ELK Stack برای مدیریت لاگ
1- نصب و تنظیم
-
- انتخاب شیوه نصب (دستی، بستهها، Docker، کلاود بیس).
- پیکربندی Elasticsearch، Logstash و Kibana مطابق با محیط خود.
2- جمعآوری لاگ
-
- تعریف پلاگینهای ورودی در Logstash برای جمعآوری لاگ از منابع مختلف (فایلها سیستم ، syslog، پایگاه دادهها و غیره).
- پیکربندی Logstash برای پارسینگ و غنیسازی دادههای لاگ در صورت نیاز.
- ارسال لاگهای پردازش شده به Elasticsearch برای ایندکس کردن.
3- ایندکس کردن داده
-
- Elasticsearch به طور خودکار دادههای لاگ ورودی را ایندکس میکند.
- بهینهسازی تنظیمات ایندکس برای عملکرد بر اساس حجم داده و الگوهای پرسوجو.
4- کاوش و تجسم داده
-
- استفاده از Kibana برای ایجاد الگوهای ایندکس بر اساس ایندکسهای Elasticsearch.
- کاوش دادههای لاگ با استفاده از ویژگی Discover Kibana.
- ساخت داشبوردها و تجسمها برای نظارت بر سلامت سیستم، شناسایی مشکلات و کسب بینش.
بهترین شیوههای پیادهسازی و مدیریت ELK Stack
ELK Stack یک ابزار قدرتمند برای مدیریت لاگها است، اما برای بهرهبرداری بهینه از آن، رعایت برخی اصول و بهترین شیوهها ضروری است. در ادامه به بررسی هر یک از این موارد میپردازیم:
چرخش لاگ (Log Rotation)
دادههای لاگ به سرعت حجم زیادی را اشغال میکنند. برای مدیریت فضای دیسک و جلوگیری از پر شدن آن، باید مکانیزمی برای حذف یا آرشیو کردن قدیمیترین لاگها وجود داشته باشد. چرخش لاگ فرآیندی است که در آن فایلهای لاگ به صورت خودکار حذف یا به فایلهای دیگری منتقل میشوند. این فرآیند را میتوان با استفاده از ابزارهای داخلی سیستم عامل یا پلاگینهای Logstash انجام داد. تنظیمات چرخش لاگ شامل تعیین مدت زمان نگهداری هر فایل لاگ، تعداد فایلهای پشتیبان و فرمت نامگذاری فایلهای آرشیو شده است.
امنیت
امنیت دادههای لاگ از اهمیت بالایی برخوردار است، زیرا این دادهها ممکن حاوی اطلاعات حساس باشند. برای محافظت از ELK Stack، باید اقدامات امنیتی زیر را انجام داد:
- احراز هویت: با استفاده از مکانیزمهای احراز هویت قوی مانند LDAP یا Active Directory، دسترسی به ELK Stack را محدود کنید.
- مجوز: به کاربران مختلف، مجوزهای دسترسی متفاوتی به دادهها و عملکردهای ELK Stack بدهید.
- رمزگذاری: برای انتقال دادهها و ذخیره آنها از رمزگذاری استفاده کنید.
- بکاپ گیری: از نسخههای پشتیبان منظم از دادههای خود تهیه کنید.
- بهروزرسانی: نرمافزارهای ELK Stack را به طور مرتب بروزرسانی کنید تا از آسیبپذیریها جلوگیری شود.
تنظیم عملکرد
عملکرد ELK Stack به عواملی مانند حجم داده، نوع پرسوجوها و سختافزار بستگی دارد. برای بهینه سازی عملکرد، میتوان اقدامات زیر را انجام داد:
- تخصیص منابع مناسب: به Elasticsearch و Logstash منابع سختافزاری کافی مانند رم و CPU اختصاص دهید.
- تنظیمات ایندکس: تنظیمات ایندکس Elasticsearch را بر اساس نوع داده و الگوهای پرسوجو بهینه کنید.
- بهینهسازی کوئریها: کوئریهای جستجو را بهینه کنید تا زمان پاسخگویی را کاهش دهید.
- کاهش دادههای تکراری: از تکرار دادهها در Elasticsearch جلوگیری کنید.
- استفاده از کش: از کش برای ذخیره نتایج پرسوجوهای پرکاربرد استفاده کنید.
مانیتورینگ
مانیتورینگ مداوم سلامت و عملکرد اجزای ELK Stack ضروری است. با استفاده از ابزارهای مانیتورینگ، میتوانید مشکلات را به سرعت شناسایی و برطرف کنید. برخی از موارد مهم برای مانیتورینگ عبارتند از:
- مصرف منابع: نظارت بر مصرف CPU، رم و دیسک.
- در دسترس بودن: اطمینان از در دسترس بودن سرویسهای Elasticsearch، Logstash و Kibana.
- عملکرد کوئریها: اندازه گیری زمان پاسخگویی کوئریها.
- خطاها و هشدارها: نظارت بر خطاها و هشدارهای سیستم.
نگهداری داده
تعیین سیاستهای نگهداری داده برای حفظ تعادل بین نیازهای تحلیل و هزینههای ذخیرهسازی بسیار مهم است. برخی از عوامل موثر در تعیین سیاستهای نگهداری داده عبارتند از:
- قوانین و مقررات: رعایت قوانین و مقررات مربوط به نگهداری دادهها.
- نیازهای قانونی: نگهداری دادهها برای مدت زمان مشخص به منظور پاسخگویی به درخواستهای قانونی.
- نیازهای تجاری: نگهداری دادهها برای تحلیلهای بلندمدت و بهبود تصمیمگیری.
- هزینه ذخیرهسازی: هزینههای ذخیرهسازی دادهها را در نظر بگیرید.
با پیروی از این بهترین شیوهها، میتوانید از ELK Stack به عنوان یک ابزار قدرتمند و کارآمد برای مدیریت لاگهای خود استفاده کنید و به بینشهای ارزشمندی دست یابید.
نگاهی اجمالی به فرایند تجزیه لاگ توسط Logstach
برای درک بهتر فرایند عملکرد ELK Stack به بررسی تجزیه لاگ (Log Parsing) می پردازیم
تجزیه لاگ گام مهمی در مدیریت لاگ است که شامل استخراج اطلاعات بامعنی از دادههای خام لاگ میشود. Logstash در این زمینه با ارائه یک چارچوب قدرتمند و انعطافپذیر برای تبدیل لاگهای بدون ساختار به دادههای ساختاریافته، بسیار کارآمد است.
درک تجزیه لاگ
تجزیه لاگ، فرآیند تبدیل متن خام لاگها به فرمتی ساختاریافته است تا برای ایندکسگذاری و تحلیل مناسب شوند. این فرآیند شامل موارد زیر است:
- شناسایی الگوها: تشخیص فرمتهای رایج لاگ (مانند آپاچی، سیسلاگ، سفارشی) و ساختار آنها.
- استخراج فیلدها: جدا کردن اطلاعات مهم از لاگها (مانند تایماستمپ، هاست، پیام، کد خطا).
- ایجاد داده ساختاریافته: تبدیل فیلدهای استخراجشده به فرمتی استاندارد (مانند JSON).
Logstash و تجزیه لاگ
Logstash از معماری pipeline (خط لوله) برای پردازش لاگها استفاده میکند:
- ورودی (Input): جمعآوری لاگها از منابع مختلف (فایلها، سیسلاگ، سوکتهای شبکه و غیره).
- فیلتر (Filter): تجزیه لاگها، استخراج فیلدها و اعمال تغییرات.
- خروجی (Output): ارسال دادههای پردازششده به Elasticsearch یا مقصدهای دیگر.
پلاگینهای فیلتر Logstash برای تجزیه لاگ ضروری هستند. برخی از پلاگینهای رایج عبارتند از:
- grok: مطابقت الگو قدرتمند برای استخراج فیلدها از فرمتهای مختلف لاگ.
- json: تجزیه لاگهای با فرمت JSON.
- csv: تجزیه لاگهای با فرمت CSV.
- multiline: مدیریت ورودیهای لاگ چندخطی.
- mutate: ایجاد و اصلاح فیلدها.
مثال: تجزیه لاگهای دسترسی آپاچی
input {
file {
path => "/var/log/apache2/access.log"
}
}
filter {
grok {
match => { "message" => "%{COMMONAPACHELOG}" }
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "apache-access-%{+YYYY.MM.dd}"
}
}این پیکربندی:
- لاگهای دسترسی آپاچی را از مسیر /var/log/apache2/access.log میخواند.
- الگوی grok با نام COMMONAPACHELOG را برای استخراج فیلدهایی مانند هاست از راه دور، روش درخواست، کد پاسخ و غیره اعمال میکند.
- دادههای تجزیه شده را به صورت روزانه به Elasticsearch با ایندکسی به نام «apache-access» ارسال میکند.
با تسلط بر تجزیه لاگ با Logstash، میتوانید از تمام پتانسیل دادههای لاگ خود برای تحلیل، عیبیابی و اهداف امنیتی بهرهمند شوید.



