
اهمیت بهینه سازی عملکرد دیتابیس
در دنیای امروز، وبسایتها و برنامههای کاربردی به طور فزایندهای پیچیدهتر میشوند و حجم دادههایی که با آنها سروکار دارند به طور پیوسته در حال افزایش است. این امر میتواند منجر به کندی و عدم کارایی دیتابیس شود، به خصوص زمانی که حجم دادهها به طور قابل توجهی افزایش یابد.
هر بار که کاربری با سایت شما تعامل دارد، وب سایت شما درخواستهایی (یا کوئریها) را به دیتابیس شما ارسال میکند و از آن میخواهد که یا یک رکورد داده جدید را ذخیره کند یا یک رکورد موجود را ارائه دهد. سرعت پردازش این کوئریها برای عملکرد کلی سایت بسیار مهم است.
انتخاب دیتابیس و DBMS مناسب
انتخاب سیستم مدیریت دیتابیس مناسب نه تنها برای عملکرد وب سایت شما بلکه برای آینده کل پروژه بسیار مهم است. با این حال، قبل از اینکه نحوه انجام آن را به شما نشان دهیم، باید چند مفهوم رااصلاح کنیم.
دو نوع اصلی دیتابیس داریم:
-
دیتابیسهای رابطهای:
دیتابیسهای رابطهای همچنین به عنوان دیتابیسهای SQL شناخته میشوند زیرا با Structured Query Language (زبان پرس و جوی ساختاریافته) کار میکنند. هر قطعه اطلاعاتی که در چنین قالبی ذخیره میکنید در یک جدول قرار میگیرد. DBMS شما روابطی بین جداول مختلف برقرار میکند تا دادهها بتوانند سریعتر و کارآمدتر بازیابی و ارائه شوند. دیتابیسهای رابطهای رویکرد سادهتری برای ذخیره دادهها در پیش میگیرند. سینتکس SQL آسان است و ساختار آن احتمال ذخیره شدن ورودیهای تکراری را از بین میبرد. برعکس، دیتابیسهای رابطهای برای کار روی یک ماشین واحد طراحی شدهاند، بنابراین نمیتوان آنها را به صورت افقی مقیاسبندی کرد. این میتواند یک مشکل باشد اگر پروژه شما به جایی برسد که یک سرور دیگر به اندازه کافی برای پشتیبانی از آن قدرت نداشته باشد.
-
دیتابیسهای غیر رابطهای:
دیتابیسهای غیر رابطهای همچنین NoSQL (به معنای Not Only SQL) نامیده میشوند. دیتابیسهای NoSQL از چندین روش ذخیرهسازی برای ذخیره اطلاعات استفاده میکنند. برخی آن را در فایلها نگه میدارند، برخی از ستونها و جداول (بدون روابط بین آنها) استفاده میکنند و برخی دیگر به شبکههای پیچیده گرهها متکی هستند. دیتابیسهای غیر رابطهای میتوانند طیف گستردهتری از ساختارهای داده را ذخیره کنند و از آنجایی که میتوانند به صورت افقی در چندین سرور مقیاس شوند – همچنین میتوانند برای وبسایتهای بزرگ با حجم عظیمی از دادهها عملکرد خوبی داشته باشند. با این حال، برای یک وبسایت معمولی که در آن با مجموعه دادههای استاندارد کار میکنید، استفاده از یک دیتابیس غیر رابطهای میتواند یک پیچیدگی غیرضروری باشد.
اما کدام یک گزینه بهتریست ؟
اینکه از دیتابیس رابطهای یا غیر رابطهای استفاده کنید بستگی به نوع سایتی دارد که میخواهید بسازید. اکثر سیستمهای مدیریت محتوا و برنامههای ساخت وبسایت مانند وردپرس، جوملا، دروپال، مجنتو و غیره از دیتابیسهای SQL استفاده میکنند و برای این کار چند دلیل وجود دارد. اول اینکه، بسیاری از این پلتفرمها میتوانند ریشههای خود را به اوایل دهه 2000 بازگردانند، زمانی که مدیریت دیتابیسهای غیر رابطهای حتی از امروز پیچیدهتر بود. دومین دلیل و دلیل مهمتر این است که دادههای تولید شده توسط اکثر برنامههای وبسایت قابل پیشبینی هستند. انواع دادههای محدودی وجود دارد و ساختار به ندرت تغییر میکند.
در نهایت، نوع دیتابیسی که استفاده میکنید بر اساس نیازهای پروژه شما تعیین میشود. همین مورد در مورد DBMS نیز صدق میکند. DBMS بین کاربر یا برنامه کاربردی و دیتابیس قرار میگیرد. این نرمافزار وظیفه رسیدگی به کوئریها بین سرویسگیرنده و سرور را بر عهده دارد.
DBMS های دیتابیس SQL :
گزینههای زیادی در این زمینه وجود دارد. اگر از دیتابیس SQL استفاده میکنید، یکی از موارد زیر را انتخاب خواهید کرد:
-
MySQL
-
MariaDB
-
Microsoft SQL Server
-
PostgreSQL
-
SQLite
انتخاب برای NoSQL محدودتر است، با محبوبترین گزینهها مانند MongoDB و Redis. برخی محصولات اختصاصی مانند Oracle DBMS با هر دو دیتابیس رابطهای و غیر رابطهای کار میکنند.
نکته اصلی این است که ببینید کدام DBMSها توسط نرمافزاری که برای ساختن سایت خود استفاده میکنید پشتیبانی میشوند. برخی از برنامهها فقط برای کار با یک فناوری خاص دیتابیس طراحی شدهاند، در حالی که برخی دیگر از چندین گزینه پشتیبانی میکنند.
اینکه کدام یک را انتخاب کنید به عوامل زیادی بستگی دارد، از جمله حجم پروژه شما، پتانسیل رشد، ابزارهایی که برای ساخت آن استفاده میکنید و بودجه. همه را به صورت جداگانه در نظر بگیرید و گزینههای نامناسب را حذف کنید تا به چند گزینه نهایی برسید.
با محدود شدن انتخابها، باید DBMSهای مختلف و ویژگیهای آنها را به صورت مقایسهای در کنار هم قرار دهید. در این مرحله متوجه خواهید شد که برخی تفاوتها بین سیستمهای مختلف میتواند مستقیماً بر عملکرد دیتابیس شما تأثیر بگذارد.برای مثال، اگر MySQL و MariaDB را به طور مستقیم با هم مقایسه کنید، خواهید دید که MariaDB گزینههای بیشتری برای بهینهسازی موتور ذخیرهسازی و سرعت دارد. اگر عملکرد یک ملاحظهی اساسی باشد، واضح است که کدام گزینه برتری دارد.در نهایت، انتخاب DBMS مناسب به یک تحلیل عمیق و ترتیب دقیق اولویتها ختم میشود.
DBMS در هاست مدیریت شده
اکثر حسابهای هاستینگ مدیریت شده با مجموعهای از فناوریها همراه هستند که شامل یک سیستم مدیریت دیتابیس نیز میشود. از آنجایی که اکثر وبسایتها با دیتابیسهای رابطهای کار میکنند، تنظیمات معمولاً شامل یک DBMS SQL است.
به طور کلی، دیتابیسهای رابطهای محبوبتر هستند، بنابراین تکنیکهای بهینهسازی که امروز به شما نشان خواهیم داد عمدتاً حول آنها میچرخند.
چگونه ایندکس کردن دیتابیس سرعت اجرای کوئری را افزایش می دهد ؟
هر چه کوئریهای دیتابیس شما سریعتر باشند، وبسایت نیز سریعتر خواهد بود. سرعت اجرای کوئری به عوامل مختلفی از جمله عملکرد سرور، تعداد اتصالات همزمان، پیکربندی کش حافظه و بافر و غیره بستگی دارد.با این حال، یکی از سادهترین راههای اطمینان از تحویل سریع دادهها، سازماندهی بهتر آن است و اگر از یک دیتابیس رابطهای استفاده میکنید، یکی از سادهترین کارها پیادهسازی یک استراتژی ایندکسسازی است. بیایید به یک مثال فرضی نگاه کنیم تا نشان دهیم که ایندکس چگونه کار میکند.
تصور کنید که یک جدول دیتابیس با 230000 سطر دارید – تقریباً برابر با تعداد ورودیهای یک فرهنگ لغت انگلیسی مدرن. ستون اول شامل شناسهها، ستون دوم برای کلمات یا عبارات و ستون سوم برای تعاریف مربوطه است. ورودیها به ترتیب الفبایی مرتب نشدهاند.
یک کاربر میخواهد تعریف کلمه “دیتابیس” را که در سطر شماره 200000 قرار دارد پیدا کند. کاری که DBMS باید انجام دهد این است که جدول را در حافظه بارگذاری کند، از ابتدا شروع کند و از هر سطر عبور کند تا سطر صحیح را پیدا کند. به عبارت دیگر، برای اجرای یک کوئری واحد، دیتابیس شما باید 199999 سطر را بخواند. این به سختی کارآمدترین رویکرد است و دلیل وجود ایندکسها همین است.
یک ایندکس یک ساختار داده جداگانه در دیتابیس است. این ساختار شامل یک کپی از یک یا چند ستون از یک جدول دیتابیس و همچنین اشاره گرهایی به مکان دادههای مربوطه است.
یک ایندکس با یک کپی از ستون حاوی کلمات و اشاره گرهایی داریم که به DBMS میگوید هر ورودی در جدول اصلی در کجا قرار دارد. از آنجایی که این یک ساختار داده جداگانه است، میتوانیم کلمات و عبارات را به ترتیب الفبایی مرتب کنیم بدون اینکه به سایر دادهها آسیبی برسانیم (مانند بهم ریختن شناسهها). مزایای چنین ایندکسی دوگانه است.
اول، DBMS از ترتیب الفبایی برای مکانیابی سریع کلمه در ایندکس استفاده میکند. به جای بررسی هر یک از 230000 کلمه و عبارت، ورودی 115000 (نقطه وسط) را در ایندکس بررسی میکند و مشخص میکند که کلمه “دیتابیس” قبل یا بعد از آن به ترتیب الفبایی قرار دارد. فرض میکنیم که در زیر ورودی 115000، کلمه “میکروسکوپ” را داریم، بنابراین “دیتابیس” قطعا بالاتر از آن است.
“میکروسکوپ” همراه با تمام ورودیهای زیر آن از جستجو حذف خواهد شد. DBMS همین فرآیند را چندین بار تکرار میکند تا ورودی “دیتابیس” را در ایندکس پیدا کند. این بسیار کارآمدتر از خواندن هر سطر در یک دیتابیس است.سپس، با پیدا کردن ورودی در ایندکس، دیتابیس مختصات بلوک دادهای را دارد که حاوی دادههای مربوطه است. در نتیجه، میتواند بدون بارگذاری کل جدول دیتابیس در حافظه، تعریف را بازیابی کند. این باعث میشود که هم سریعتر و هم کارآمدتر باشد.
آیا معایبی هم وجود دارد؟ بله ، به عنوان یک ساختار جداگانه، ایندکس به طور اجتنابناپذیری از فضای ذخیرهسازی اضافی استفاده میکند. علاوه بر این، شما باید ستونهایی را که به ایندکسهای خود اضافه میکنید با دقت انتخاب و ترکیب کنید. در حالت ایدهآل، میخواهید دادههایی را ایندکس کنید که اغلب جستجو و استفاده میشوند.
ایجاد ایندکس دیتابیس
یکی از گزینهها استفاده از دستور SQL CREATE INDEX است. این دستور به خوبی مستند شده است و نباید برای افرادی که تجربه SQL دارند چالش زیادی ایجاد کند. کسانی که با کار کردن در کامند لاین احساس راحتی نمیکنند، ترجیح میدهند از یک ابزار مبتنی بر رابط کاربری گرافیکی مانند phpMyAdmin استفاده کنند.
مراحل به شرح زیر است:
- 1 ) phpMyAdmin را از طریق کنترل پنل خود باز کنید. اگر از SPanel استفاده میکنید، میتوانید آیکون آن را در بخش دیتابیسها در صفحه اصلی رابط کاربری پیدا کنید.
- 2 ) دیتابیسی را که میخواهید تغییر دهید از منوی سمت چپ انتخاب کنید.
![]()
- 3 ) صفحه اصلی اکنون تمام جداول موجود در دیتابیس انتخاب شده را نشان میدهد. روی جدولی که میخواهید ایندکس کنید کلیک کنید.
![]()
- 4 ) به تب Structure بروید. تمام ستونهای جدول را مشاهده خواهید کرد. از کادرهای انتخاب برای انتخاب ستونهایی که میخواهید به ایندکس اضافه کنید استفاده کنید و روی دکمه Index زیر لیست کلیک کنید.
![]()
اگر دادهها خراب نشده باشند، phpMyAdmin باید پیامی مبنی بر موفقیتآمیز بودن عملیات نمایش دهد.
مدیریت حافظه و تخصیص بافر (Buffering)
بافرینگ در مورد استفاده کارآمد از منابع سخت افزاری موجود است. به طور خاص، نشان میدهد که سیستم مدیریت دیتابیس شما چگونه از RAM سرور برای سرعت بخشیدن به اجرای کوئری استفاده میکند.هر زمان که DBMS نیاز به خواندن یا نوشتن اطلاعات از یا به دیتابیس داشته باشد، یک کپی از رکورد را در حافظه سرور ذخیره میکند. سپس، درخواستی برای همان قطعه داده دریافت میکند و کپی را از RAM بازیابی میکند.
چرا این کار را انجام میدهد؟
همه اینها به این دلیل است که سرویسدهی دادهها از حافظه بسیار سریعتر از انجام آن از دیسک است. تفاوت سرعت به عوامل زیادی بستگی دارد، اما حتی زمانی که NVMe SSDهای پیشرفته را با RAM استاندارد مقایسه میکنید، در مورد عملکرد چندین برابر سریعتر هنگام خواندن دادهها از حافظه صحبت میکنیم. همانطور که حدس زدهاید، این همه تأثیر عمیقی بر سرعت بارگذاری کلی و تجربه کاربر دارد.
بدیهی است که حافظه سرور نامحدود نیست، بنابراین دیتابیس نمیتواند حجم نامحدودی از داده را در آن ذخیره کند. در واقع، دیتابیس شما یک حجم اختصاصی از حافظه دارد که مخصوصاً برای کش کردن دادهها رزرو شده است. به آن بافر میگویند و اگر سایت شما از موتور ذخیرهسازی InnoDB استفاده میکند، ظرفیت پیشفرض آن 128 مگابایت است.
با این حال، به خاطر داشته باشید که افزایش اندازه بافر لزوماً همه مشکلات شما را حل نمیکند.این تا حدی به این دلیل است که اختصاص دادن RAM بیشتر به بافر میتواند سایر اجزای حیاتی برای عملکرد سایت شما را از منابع مورد نیاز برای اجرای خوب محروم کند. همچنین تضمین نمیشود که اندازه بافر اصلیترین مانع عملکرد باشد.
به همین دلیل، اگر مشکلی در بافر دیتابیس وجود دارد، میخواهید دقیقتر به موضوع نزدیک شوید.
در اینجا چند شاخص وجود دارد که ممکن است بخواهید به آنها توجه کنید:
-
نرخ برخورد بافر (The buffer pool hit ratio):
این معیار به شما نشان میدهد که چه درصدی از کل کوئریها توسط بافر پاسخ داده میشوند و چه مقدار به دیسک میرود. به طور پیش فرض، DBMS تا حد امکان کوئریها را از طریق بافر پردازش میکند. با این حال، اگر درخواست برای صفحهای باشد که در حافظه ذخیره نشده است، به دیسک منتقل میشود و پردازش آن بسیار کندتر خواهد بود.
به همین دلیل، حفظ حداکثر نرخ برخورد بافر ضروری است. کارشناسان توصیه میکنند دیتابیس خود را طوری پیکربندی کنید که حدود 90٪ از کل کوئریها توسط بافر مدیریت شوند.
-
میانگین عمر صفحه (Page life expectancy):
هر کپی از یک رکورد ذخیره شده در بافر پس از مدتی حذف میشود. هر چه دیتابیس شلوغتر باشد، این دوره کوتاهتر است. نظارت بر اینکه رکوردهای داده با چه سرعتی از بافر حذف میشوند، به شما میانگین عمر صفحه را میدهد – معیاری که میتواند به شما در بهبود عملکرد دیتابیس کمک کند.
به طور سنتی پذیرفته شده است که یک عمر صفحه معقول در حدود 300 ثانیه است. با این حال، این نتیجه زمانی حاصل شد که سرورها کمتر قدرتمند بودند. امروزه، داشتن میانگین عمر صفحه 300 ثانیه برای هر 4 گیگابایت رم طبیعی در نظر گرفته میشود.هر چه سرور شلوغتر باشد، صفحات باید با سرعت بیشتری از بافر حذف شوند. این باعث کاهش عمر صفحه و افزایش تعداد درخواستهایی میشود که نمیتوانند توسط بافر پردازش شوند. از آنجایی که دیسک بسیار کندتر است، عملکرد کلی وبسایت به ناچار تحت تأثیر قرار میگیرد.
-
تعداد صفحات خوانده شده در ثانیه: (Page reads/sec):
این معیار نشان میدهد که هر ثانیه چه مقدار داده از دیسک خوانده میشود. شما میخواهید آن را تا حد ممکن پایین نگه دارید زیرا صرف نظر از سرعت SSDهای مدرن، کوئریهایی که توسط دیسک سرور مدیریت میشوند هنوز هم نسبتاً کند هستند.
روشهای زیادی برای به حداقل رساندن نقش دیسک در اجرای کوئری دیتابیس وجود دارد. میتوانید این کار را با ارائه یک بافر با اندازه مناسب که دادههای جستجوی مکرر را کش میکند انجام دهید، اما همچنین میتوانید اطمینان حاصل کنید که اطلاعات به درستی ایندکس شده است تا DBMS بتواند سریعتر آن را پیدا کند.
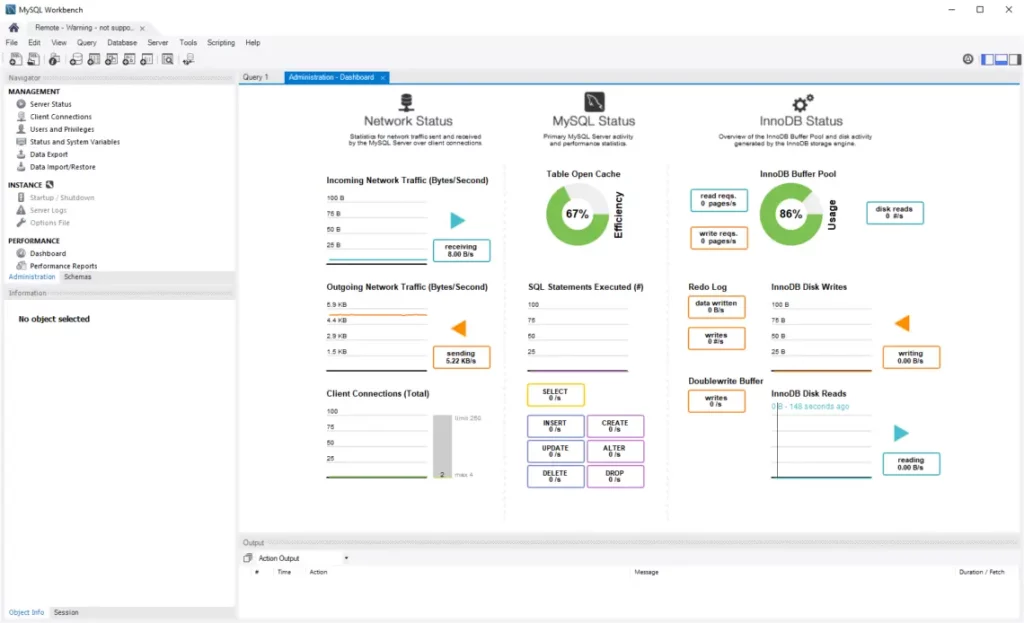
روشهای زیادی برای نظارت بر سلامت استخر بافر دیتابیس شما وجود دارد. برای مثال، MySQL Workbench، یک ابزار مدیریت دیتابیس رایگان مبتنی بر رابط کاربری گرافیکی، دارای یک داشبورد عملکرد است که انواع مختلف آمار از جمله استفاده از استخر بافر، درخواستهای write/read، خواندن دیسک در ثانیه و غیره را نشان میدهد.
تغییر اندازه بافر پیچیدهتر است. این کار مستلزم تغییر فایل پیکربندی اصلی MySQL به نام my.cnf است. مکان دقیق آن به سیستم عامل بستگی دارد. اکثر توزیعهای لینوکس مبتنی بر Red Hat آن را در /etc/ folder ذخیره میکنند. متغیری که باید اضافه یا تغییر دهید به موتور ذخیرهسازی بستگی دارد. اگر از InnoDB استفاده میکنید، innodb_buffer_pool_size است. برای دیتابیسهای مبتنی بر key_buffer_size ، MyISAM است.
استفاده از مکانیسمهای کش
همانطور که در بخش قبلی کشف کردیم، دیتابیس رابطهای شما یک مکانیسم داخلی برای ذخیره اطلاعات در حافظه برای بازیابی سریعتر دارد. به عبارت دیگر، به طور موثر دارای یک سیستم کش می ی باشد . با توجه به این موضوع، ممکن است فکر کنید پیادهسازی سایر راهحلهای کش غیرضروری است.این کاملا درست نیست.
بیشتر راهحلهای کش روی دادههای استاتیک مانند تصاویر، استایلشیتهای CSS و فایلهای جاوا اسکریپت تمرکز میکنند، اما برخی از سیستمهای پیشرفته همچنین میتوانند دادههای تولید شده توسط دیتابیس را در RAM سرور برای سرعت بخشیدن به ارائه ذخیره کنند.
آنها در بسیاری از حوزههای کلیدی از بافر پیشفرض بهتر عمل میکنند، از جمله:
-
روش ذخیرهسازی کش:
بافر دیتابیس شما حاوی صفحات اطلاعات با چندین ردیف و رکورد جدول است. کشهای ساخته شده توسط راهحلهای اختصاصی تمایل دارند بسیار سازماندهی شدهتر باشند.
-
مکانیسم بازیابی داده:
راهحلهای کش از سیستمهای پیچیده key/value برای مکانیابی دادههای مورد نیاز استفاده میکنند که منجر به تحویل بسیار سریعتر میشود.
-
مقیاسپذیری:
راهحلهای کش اختصاصی با در نظر گرفتن پروژههای با هر شکل و اندازهای ساخته شدهاند. در نتیجه، میتوانند از پروژه شما پشتیبانی کنند و حتی با رشد سایت شما عملکرد عالی را تضمین کنند.
دهها سیستم کش با مزایا و معایب خود وجود دارد. با این حال، هنگامی که صحبت از کش دیتابیس میشود، دو راهحل از بقیه برجستهتر هستند. بیایید نگاهی به آنها بیندازیم.
Memcached : راهکار کش محبوب و کارآمد
Memcached یک راهکار کش محبوب است که برای اولین بار بیش از دو دهه پیش منتشر شد و در طول سالها به جزء جداییناپذیر بسیاری از مجموعههای توسعه تبدیل شده است. این سیستم به دلیل تطبیقپذیری پیشرفتهاش در بین صاحبان وبسایت محبوب است. Memcached از اکثر زبانهای برنامهنویسی محبوب پشتیبانی میکند و دارای یک رابط برنامهنویسی کاربردی (API) آسان برای استفاده است، بنابراین پیکربندی برنامه شما برای کار با آن نباید مشکلی ایجاد کند. افزونهای ویژه برای پایگاههای داده MySQL راهاندازی سریع و آسان را امکانپذیر میکند.
Memcached همچنین از معماری توزیعشده پشتیبانی میکند، به این معنی که دادههای کششده میتوانند به طور همزمان روی چندین گره (node) ذخیره شوند. این کار ممکن است کمی پرهزینه به نظر برسد، اما به لطف راهحلهای کانتینریزه و مجازیسازی مانند Docker و Kubernetes، لزوماً اینطور نیست.
استفاده از چندین گره نه تنها بار را توزیع میکند و عملکرد را بهبود میبخشد، بلکه زمان خرابی احتمالی را نیز به حداقل میرساند. به همین دلیل است که در گذشته، حتی شبکههای اجتماعی بزرگی مانند توییتر از Memcached استفاده میکردند. با این حال، اکنون آنها یک سیستم کش دیگر را نیز پیادهسازی کردهاند.
Redis :
Redis، که در سال 2009 منتشر شد، شباهتهایی به Memcached دارد، زیرا متنباز است و توسط اکثر ارائه دهندگان هاستینگ پشتیبانی میشود. مانند Memcached، دادهها را در حافظه سرور ذخیره میکند تا تحویل سریعتر شود.
بر خلاف رقیب بازار خود، دادههایی که Redis در حافظه مینویسد پایدار هستند – فایلهای snapshot و لاگها اطلاعات را هنگام راهاندازی بازیابی میکنند. این ویژگی به همراه سیستم بازیابی داده کلید-مقدار، به این معنی است که Redis میتواند به عنوان یک سیستم مدیریت دیتابیس غیررابطهای با ویژگیهای کامل استفاده شود.
اگر از یک دیتابیس SQL استفاده میکنید، Redis را میتوان به عنوان یک راهحل کش پیادهسازی کرد. Redis از انواع داده پشتیبانی میکند، چیزی که Memcached فاقد آن است، و طیف وسیعی از زبانها و برنامههای کاربردی که Redis با آنها کار میکند حتی چشمگیرتر است.
به طور کلی، چندین ویژگی Redis را قدرتمندتر و انعطافپذیرتر از Memcached میکنند. با این حال، هر دو راهحل میتوانند سرعت دیتابیس شما را به طور قابل توجهی افزایش دهند، بنابراین در نظر گرفتن آنها یک تصمیم خوب است.
بهینه سازی دیسک I/O
تقریباً تمام تکنیکهای بهینهسازی در نهایت با هدف کاهش تعداد عملیات خواندن و نوشتن دیسک (دیسک I/O) انجام میشوند.
به لطف ایندکسها، DBMS نیازی به اسکن کل جدول در هر بار نیاز به یک قطعه داده ندارد و با کمک بافرینگ، بسیاری از کوئریها توسط حافظه دسترسی تصادفی سرور به جای دیسک بسیار کندتر مدیریت میشوند.
با این حال، اگر اندازه دیتابیس شما به اندازه کافی بزرگ شود، حجم دادهها بسیار بزرگ خواهد بود و جستجوها برای روشهای بهینهسازی فوق بسیار تصادفی خواهند بود. دیسک I/O علیرغم بهترین تلاشهای شما افزایش مییابد.
متأسفانه، برخورد با این مشکل به سادگی که فکر میکنید نیست. تا حدی به این دلیل است که تشخیص مشکل به برخی دانش فنی نیاز دارد و تا حدی به این دلیل که DBMSها و موتورهای ذخیرهسازی مختلف جنبههای مختلفی از عملیات خود دارند که ممکن است بر I/O تأثیر بگذارند.
هیچ راهحل جهانی پشتیبانیشدهای وجود ندارد که بتواند تعداد عملیات ورودی و خروجی دیسک شما را کاهش دهد. با این حال، چند تکنیک وجود دارد که باید در اکثر موارد کار کند:
بهینه سازی جداول و ایندکسها
برای کاهش سربار دیسک، ابتدا باید به سادهترین روش ممکن یعنی بهینهسازی جداول و ایندکسها بپردازیم. یک دیتابیس فعال با هزاران درخواست برای درج، تغییر و حذف اطلاعات در جداول مواجه میشود. هر چه تعداد این درخواستها بیشتر باشد، دادهها نامنظمتر میشوند.
بیشتر سیستمهای مدیریت دیتابیس (DBMS) دارای مکانیسمهای داخلی برای مرتبسازی مجدد اطلاعات به منظور سرعت بخشیدن به اسکنها و تحویل سریعتر رکورد صحیح هستند. برای مثال، در MariaDB و MySQL، این کار با استفاده از دستور OPTIMIZE TABLE انجام میشود. در PostgreSQL، از دستور VACUUM استفاده میشود.
توصیه میشود به عنوان بخشی از نگهداری منظم دیتابیس، به طور دورهای از این ابزارها استفاده کنید. اگر با کار کردن در خط فرمان راحت نیستید، ابزارهایی مانند phpMyAdmin این قابلیت را از طریق یک رابط گرافیکی ارائه میدهند.
پارتیشنبندی
پارتیشنبندی به معنای تقسیم جداول بزرگ دیتابیس به قسمتهای کوچکتر و قابل مدیریتتر است. پارتیشنهای جداگانه را میتوان روی سیستمهای فایل مختلف میزبانی کرد، به این معنی که بار به طور مساویتر پخش میشود و منابع بیشتری برای تضمین سرعت بارگذاری سریع در دسترس است. علاوه بر این، تقسیم جدول بزرگ به قطعات کوچکتر به DBMS امکان میدهد اطلاعات مورد نیاز را سریعتر پیدا کند و عملکرد کلی دیتابیس را بهبود بخشد.
تنظیم نقاط بررسی (Checkpoint)
یک نقطه بررسی به DBMS میگوید هرگونه داده اصلاح شده را از حافظه کپی کند و آن را برای ذخیره دائمی روی HDD یا SSD سرور ذخیره کند. داشتن نقاط بررسی منظم تضمین میکند که تغییراتی که در دیتابیس خود ایجاد میکنید ذخیره میشود و هیچ دادهای از بین نمیرود.
با این حال، هر نقطه بررسی به طور اجتنابناپذیری باعث فعال شدن دیسک می شود. روشهایی برای تعدیل این فعالیت وجود دارد.میتوانید نقاط بررسی خود را در دورههای کم ترافیکتر سایت تنظیم کنید تا از افزایش ناخواسته فرایند های I/O جلوگیری کنید. علاوه بر این، نقاط بررسی دارای یک ویژگی زمانبندی هستند که در صورت طولانی شدن عملیات نوشتن، آن را لغو میکند. این میتواند بخشی از فشار روی دستگاه ذخیرهسازی اصلی سرور شما را در زمان بار سنگین کاهش دهد.
VPSهای مدیریت شده میتوانند به شما در رفع این مشکل کمک کنند. این نوع از VPSها با ارائه طیف وسیعی از ابزارها و خدمات بهینه سازی، به شما کمک میکنند تا عملکرد دیتابیس خود را بهینه کنید و از کندی و عدم کارایی آن جلوگیری کنید.
بهبود عملکرد دیتابیس ممکن است چالشبرانگیز به نظر برسد، اما با درک عوامل مختلفی که بر آن تأثیر میگذارند، میتوان به نتایج قابل توجهی دست یافت.خوشبختانه، استفاده از یک VPS مدیریت شده میتواند بسیاری از پیچیدگیهای این فرآیند را کاهش دهد، زیرا متخصصان هاستینگ به تنظیم و بهینهسازی دیتابیس میپردازند. با این حال، داشتن دانش پایه در مورد نحوه عملکرد دیتابیس و عوامل مؤثر بر آن میتواند به شما کمک کند تا در صورت لزوم، تغییرات لازم را اعمال کنید.



