فایل سیستم در لینوکس چیست ؟
فایل سیستم روشی برای سازماندهی و ذخیره دادهها در حافظه غیر فرار یا eNon-Volatil ( دیتا استوریجی که با خاموش شدن سیستم و همچنین قطع جریان الکتریسیته ، داده هایی که روی آن ها ذخیره شده اند از بین نمی روند و حفظ میشوند ) در یک سیستم مبتنی بر لینوکس است. این سیستم ساختار، سازماندهی و روشهای دسترسی به فایلها و دایرکتوریها را تعریف میکند. لینوکس از چندین فایل سیستم مختلف پشتیبانی میکند که هر کدام ویژگیها و موارد استفاده خاص خود را دارند.
فایل سیستمهای رایج لینوکس
- ext4: فایل سیستم پیشفرض برای اکثر توزیعهای مدرن لینوکس، با ویژگیهایی مانند ژورنالینگ، متادیتای پیشرفته و پشتیبانی از فایلهای بزرگ.
- XFS: یک فایل سیستم محبوب دیگر لینوکس، شناخته شده به دلیل عملکرد و مقیاسپذیری بالا.
- Btrfs: یک فایل سیستم نسبتا جدید که ویژگیهایی مانند copy-on-write ، snapshots و RAID داخلی را ارائه میدهد.اسنپشات به معنای یک عکس فوری یا یک نسخه کپی از یک سیستم یا داده در یک لحظه خاص است. این نسخه کپی، شامل تمام اطلاعات و تنظیمات سیستم در آن لحظه بوده و میتواند برای بازیابی سیستم به حالت قبلی یا تحلیل تغییرات ایجاد شده مورد استفاده قرار گیرد.
- ReiserFS: یک فایل سیستم ژورنالینگ که زمانی محبوب بود اما در سالهای اخیر از محبوبیت آن کاسته شده است.
- JFS: یک فایل سیستم ژورنالینگ توسعهیافته توسط IBM، شناخته شده به دلیل عملکرد و مقیاسپذیری آن.
مکانیزم فایل سیستم چگونه است ؟
فایل سیستمهای لینوکس معمولاً از یک ساختار مشابه پیروی میکنند که شامل موارد زیر است:
- متادیتا (meta data): اطلاعاتی در مورد فایلها و دایرکتوریها، مانند نامها، اندازه، تاریخ ایجاد و مجوزهای آنها.
- بلوکهای داده: دادههای واقعی ذخیره شده در دستگاه ذخیرهسازی.
- Inodes : ساختارهای دادهای که حاوی اطلاعاتی در مورد فایلها هستند، مانند متادیتای آنها و مکان بلوکهای داده آنها.
هنگامی که یک فایل ایجاد میشود، فایل سیستم بلوکهای دادهای را برای ذخیره محتوای فایل اختصاص میدهد. همچنین یک inode ایجاد میکند تا متادیتای فایل و مکان بلوکهای داده آن را ذخیره کند. هنگامی که به یک فایل دسترسی پیدا میشود، فایل سیستم از inode برای یافتن بلوکهای داده فایل و بازیابی محتوا استفاده میکند.
ساختار دایرکتوری در لینوکس
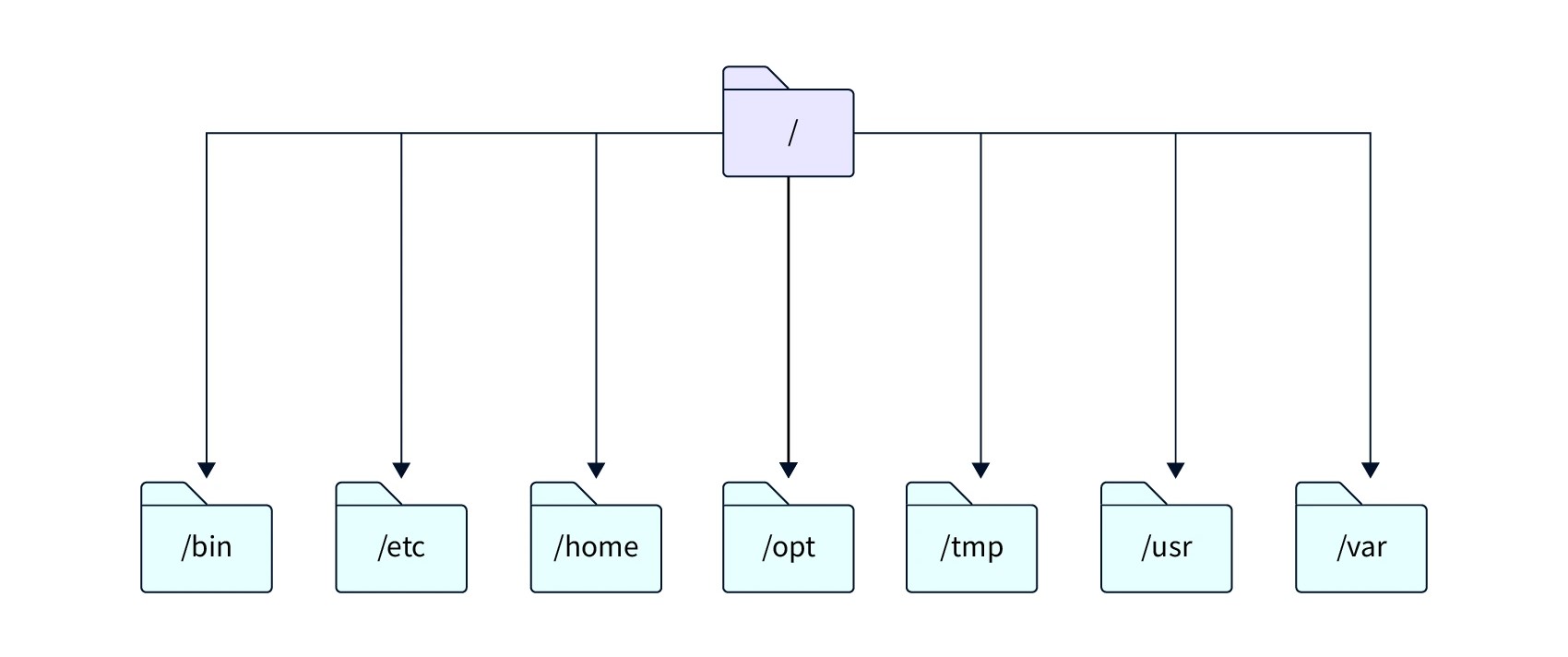
دایرکتوریها، که به عنوان پوشهها نیز شناخته میشوند، بخش جدایی ناپذیر از فایل سیستم لینوکس هستند. آنها به عنوان محفظههایی برای فایلها و دایرکتوریهای دیگر عمل میکنند و برای سازماندهی و ساختاربندی فایل سیستم استفاده میشوند. یک دایرکتوری را میتوان به عنوان یک محفظه مجازی تصور کرد که فایلها و دایرکتوریهای دیگر را در خود جای میدهد.
یکی از عملکردهای اصلی دایرکتوریها در لینوکس، ارائه یک ساختار سلسلهمراتبی برای سازماندهی فایلها است. این ساختار از دایرکتوری ریشه یا root (/) شروع میشود و در صورت نیاز به زیردایرکتوریها تقسیم میشود. با کمک این ساختار سلسلهمراتبی، سیستمهای پیچیده میتوانند به صورت منطقی ساختاردهی و سازماندهی شوند. این امر یافتن و مدیریت فایلها در سیستم را سادهتر میکند.
کاربردهای فایل سیستمهای لینوکس
فایل سیستمهای لینوکس برای اهداف مختلفی استفاده میشوند، از جمله:
- ذخیره فایلها: فایلهای از همه نوع، مانند اسناد، تصاویر، ویدیوها و برنامههای اجرایی.
- سازماندهی فایلها: گروهبندی فایلها در دایرکتوریها یا پوشهها برای مدیریت آسانتر.
- ارائه دسترسی به فایلها: اجازه دادن به کاربران برای ایجاد، اصلاح و حذف فایلها.
- محافظت از فایلها: پیادهسازی اقدامات امنیتی برای جلوگیری از دسترسی غیرمجاز به فایلها.
اما هنگاهی که با مقیاس بزرگی از دیتا مواجه هستیم دیگر فایل سیستم های ساده پاسخگوی ذخیره سازی و سازماندهی فایل ها و اطلاعات نیستند و باید به سراغ ابزاری برویم که بتواند حجم عظیمی از دادهها را مدیریت کند، مقیاسپذیر باشد، قابلیت اطمینان بالایی داشته باشد و در برابر خطاها مقاوم باشد. در چنین مواردی، سیستمهای فایل توزیعشده وارد عمل میشوند.
سیستمهای فایل توزیعشده مجموعهای از چندین سرور هستند که به صورت یکپارچه عمل میکنند و یک فایل سیستم واحد را شبیهسازی میکنند. این سیستمها به شما امکان میدهند تا دادههای خود را در چندین سرور توزیع کنید و در نتیجه ظرفیت ذخیرهسازی و عملکرد سیستم را افزایش دهید. همچنین، در صورت بروز مشکل در یک سرور، دادههای شما در سرورهای دیگر ایمن باقی میمانند.
فایل سیستمهای توزیع شده لینوکس برای ذخیره سازی در مقیاس بزرگ: Ceph و GlusterFS
با انفجار اطلاعات در عصر دیجیتال، فایل سیستمهای سنتی دیگر قادر به پاسخگویی به نیازهای رو به رشد سازمانها نیستند. این سیستمها با محدودیتهایی از قبیل مقیاسپذیری پایین، تکنقطه خرابی و هزینههای بالای نگهداری مواجه هستند. حجم عظیم دادهها، تنوع آنها و نیاز به دسترسی سریع و همزمان به اطلاعات، ضرورت استفاده از راهکارهای جدید و کارآمدتر را بیش از پیش آشکار ساخته است.
فایل سیستمهای توزیعشده همچون Ceph و GlusterFS به عنوان نسل جدیدی از سیستمهای ذخیرهسازی، با ارائه قابلیتهایی نظیر مقیاسپذیری نامحدود، تحملپذیری خطا و عملکرد بالا، به این چالش پاسخ دادهاند.
سیستمهای توزیع شده برای ذخیرهسازی در مقیاس بزرگ در لینوکس، مانند Ceph و GlusterFS، برای مدیریت دادهها در محیطهای ابری، مراکز داده، و سیستمهای با حجم بالای داده طراحی شدهاند. هر دوی این سیستمها مزایا و معایب خاص خود را دارند و بسته به نیاز و کاربردهای مختلف، یکی از آنها ممکن است مناسبتر باشد.
Ceph
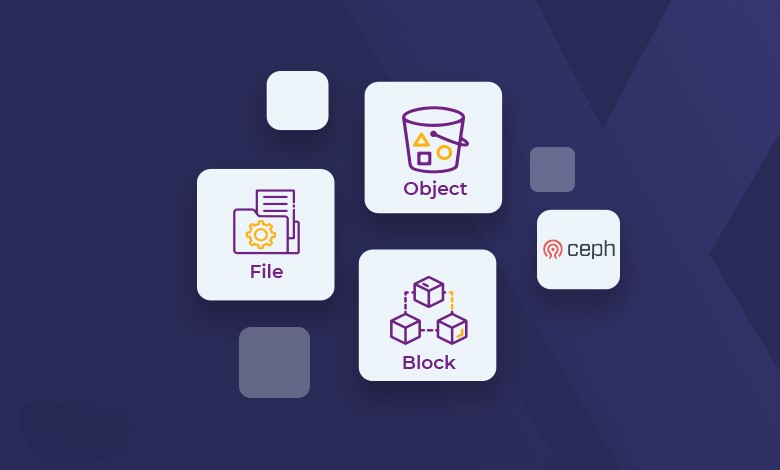
Ceph یک سیستم توزیعشده با پشتیبانی از ذخیرهسازی شیگرا، بلوکی، و فایلسیستم که با استفاده از الگوریتمهای پیشرفته و قابل تنظیم، دادهها را در سرورهای مختلفی که به صورت یک کلاستر عمل میکنند، توزیع میکند.این سرورها به صورت فیزیکی یا مجازی میتوانند در شبکههای محلی یا ابری قرار گرفته باشند. Ceph از معماری بدون نقطه شکست (Single Point of Failure – SPOF) بهره میبرد و به صورت خودکار دادهها را در سراسر نودهای سیستم توزیع و مدیریت میکند.

چگونگی کارکرد GlusterFS
GlusterFS با ایجاد یک فایلسیستم منطقی واحد از چندین سرور فیزیکی، امکان ذخیرهسازی و دسترسی به دادهها را به صورت توزیعشده فراهم میکند. این کار از طریق چند مرحله کلیدی انجام میشود:
1. ایجاد کلاستر GlusterFS:
- انتخاب سرورها: سرورهایی که قرار است به خوشه اضافه شوند، انتخاب و پیکربندی میشوند.
- نصب GlusterFS: نرمافزار GlusterFS بر روی همه سرورها نصب میشود.
- ایجاد حجم: یک حجم منطقی (volume) ایجاد میشود که نشاندهنده فضای ذخیرهسازی قابل استفاده است.
2. توزیع دادهها:
- تکهتکه شدن دادهها: دادهها به تکههای کوچکتری تقسیم میشوند که به آنها آجر (brick) گفته میشود.
- توزیع آجرها: این آجرها به صورت توزیعشده در سراسر سرورهای کلاستر قرار میگیرند.
- تکرار دادهها: برای افزایش قابلیت اطمینان، هر آجر ممکن است در چندین سرور کپی شود.
3. مدیریت متادیتا:
- سرورهای متادیتا: سرورهای متادیتا مسئول نگهداری اطلاعات مربوط به آجرها، مکان قرارگیری آنها و همچنین سلسله مراتب دایرکتوریها هستند.
- توزیع متادیتا: اطلاعات متادیتا نیز به صورت توزیعشده در بین سرورهای متادیتا ذخیره میشود.
4. دسترسی به دادهها:
- درخواست کاربر: هنگامی که کاربری به یک فایل در حجم GlusterFS دسترسی پیدا میکند، درخواست او به سرورهای متادیتا ارسال میشود.
- یافتن آجرها: سرورهای متادیتا آدرس آجرهای تشکیلدهنده فایل مورد نظر را پیدا میکنند.
- خواندن یا نوشتن دادهها: سیستم به طور خودکار دادهها را از آجرهای مربوطه خوانده یا در آنها مینویسد.
5. توازن بار:
- توزیع یکنواخت بار: GlusterFS به صورت مداوم بار کاری را بین سرورهای مختلف توزیع میکند تا از استفاده بهینه از منابع و جلوگیری از ایجاد نقاط تکنقطه خرابی اطمینان حاصل شود.
6. مدیریت خطا:
- تشخیص خطا: GlusterFS به طور مداوم وضعیت سرورها و آجرها را بررسی میکند و در صورت بروز خطا، آن را تشخیص میدهد.
- بازیابی دادهها: در صورت خرابی یک سرور یا آجر، دادههای از دست رفته از کپیهای موجود بازیابی میشوند.
Ceph در مقایسه با GlusterFS چگونه عمل میکند ؟
Ceph
- ذخیره سازی مبتنی بر شی: Ceph دادهها را به صورت اشیاء ذخیره میکند که انعطافپذیری و مقیاسپذیری را فراهم میکند.
- خود ترمیمشوندگی: Ceph میتواند به طور خودکار خرابی دادهها و خطاهای گرهها را ترمیم کند و در نتیجه در دسترس بودن بالا را تضمین کند.
- محدوده گستردهای از موارد استفاده: Ceph میتواند برای بارهای کاری مختلف، از جمله ذخیرهسازی شی، ذخیرهسازی بلوکی و سیستمهای فایل استفاده شود.
- معماری پیچیده: Ceph نسبت به GlusterFS دارای معماری پیچیدهتری است و نیاز به مدیریت پیشرفتهتری دارد.
GlusterFS
- فایل سیستم شبکهای: GlusterFS یک سیستم فایل شبکهای سنتی است که نمایشی یکپارچه از ذخیرهسازی در چندین سرور ارائه میدهد.
- معماری سادهتر: GlusterFS دارای معماری سادهتر است و نسبت به Ceph مدیریت آن آسانتر است.
- یکپارچگی قویتر با فایل سیستمهای سنتی: GlusterFS میتواند به راحتی در محیطهای سیستم فایل موجود ادغام شود.
- محدودیت در عملیات فایل سیستم: GlusterFS در درجه اول بر عملیات سیستم فایل تمرکز دارد و ممکن است برای بارهای کاری دیگر انعطافپذیری کمتری داشته باشد.