
تصور کنید در حال رانندگی با خودروی خود در یک اتوبان پرسرعت هستید و ناگهان متوجه میشوید یک قطعه کوچک و به ظاهر بیاهمیت در موتور، کل خودرو را از کار میاندازد. یا فکر کنید یک زنجیر فولادی عظیم، فقط به یک حلقه نازک متصل باشد و با پاره شدن همان یک حلقه، تمام زنجیر از هم گسسته شود. SPOF (Single Point of Failure) یا “نقطه واحد شکست” یعنی یک نقص کوچک در یک نقطه حساس میتواند به سقوط کل سیستم منجر شود.
پایداری و دسترسیپذیری سیستمها (Uptime) برای کسبوکارها و کاربران حیاتی است. یک لحظه قطعی میتواند به ضررهای مالی هنگفت، از دست رفتن اعتبار و نارضایتی مشتریان منجر شود. در این مقاله جامع، به بررسی عمیق SPOF، چرایی اهمیت آن، عواقب پنهان و استراتژیهای مقابله با آن خواهیم پرداخت. آمادهاید تا از فاجعه پنهان جلوگیری کنید؟
🎯 SPOF چیست؟
Single Point of Failure (SPOF) به هر جزء، مؤلفه، سرویس یا فرآیندی در یک سیستم (چه سختافزاری، چه نرمافزاری، چه شبکهای و حتی انسانی) اطلاق میشود که خرابی آن به تنهایی میتواند منجر به از کار افتادن یا اختلال کامل در کل سیستم شود. به عبارت سادهتر، اگر آن نقطه از کار بیفتد، تمام سیستم سقوط میکند.
🔹 چرا SPOFها خطرناک هستند؟
سیستمهای مدرن، چه یک وبسایت ساده باشند و چه یک زیرساخت ابری پیچیده برای یک شرکت بزرگ، از هزاران مؤلفه تشکیل شدهاند. وجود یک SPOF به این معنی است که امنیت، پایداری و عملکرد کل این سیستم به درستی کار کردن فقط یک عنصر واحد بستگی دارد. این یک ریسک غیرقابل قبول در دنیای امروز است.
💡 فکر کنید یک شهر بزرگ برای تأمین آب آشامیدنی خود، فقط به یک چاه و یک منبع متکی باشد. اگر آن چاه خشک شود یا منبع از بین برود، کل شهر دچار بحران آب خواهد شد. یک سیستم ایدهآل باید چندین چاه و روشهای جایگزین برای تأمین آب داشته باشد.
مثلاً، شرکتهای بزرگ فناوری مانند Google یا Amazon صدها هزار سرور در دیتاسنترهای مختلف و در سراسر جهان دارند. این توزیع جغرافیایی و سختافزاری تنها برای بالانس کردن ترافیک نیست؛ بلکه برای این است که اگر یک سرور، یک دیتاسنتر، یا حتی یک منطقه جغرافیایی دچار مشکل شد (مثلاً بلایای طبیعی، قطعی برق گسترده)، سایر سرورها و دیتاسنترها بتوانند وظیفه را به عهده گرفته و سرویسدهی را بدون وقفه ادامه دهند. به همین ترتیب، در سطح یک سرور، استفاده از آرایههای دیسکی RAID تضمین میکند که خرابی یک هارد دیسک به از دست رفتن دادهها و توقف سرویس منجر نشود.
وابستگی مطلق سیستم به یک جزء SPOF، تأثیر فاجعهباری خواهد داشت
📉 عواقب پنهان SPOF:
نادیده گرفتن SPOFها میتواند عواقب فاجعهباری به همراه داشته باشد که تنها محدود به یک قطعی ساده نیست:
- 🔻📉 کاهش قابلیت اطمینان (Reliability Degradation): وجود SPOF، اعتماد کاربران، مشتریان و حتی ذینفعان داخلی به سیستم شما را به شدت کاهش میدهد. در دنیای رقابتی امروز، یک تجربه بد میتواند به معنای از دست دادن مشتریان برای همیشه باشد.
- 💸 هزینههای گزاف (Exorbitant Costs): خرابی یک SPOF میتواند دهها، صدها میلیون یا حتی میلیاردها تومان به همراه داشته باشد. این هزینهها شامل:
- هزینههای مستقیم: تعمیر و نگهداری، جایگزینی سختافزار/نرمافزار، جبران خسارت.
- هزینههای غیرمستقیم: از دست دادن درآمد در زمان قطعی، از دست رفتن فرصتهای فروش، جریمههای ناشی از نقض قرارداد سطح سرویس (SLA).
- هزینههای نامرئی: آسیب به شهرت برند (Brand Reputation Damage)، کاهش روحیه کارکنان، و هزینه بازگرداندن اعتماد.
- ⏰ افزایش زمان خاموشی (Extended Downtime): SPOFها معمولاً به قطعیهای طولانیمدتتر منجر میشوند، زیرا تشخیص و رفع مشکل در یک نقطه حیاتی میتواند زمانبر باشد. این قطعیها به طور مستقیم بر فعالیتهای کسبوکار تأثیر منفی میگذارند و زنجیره عملیاتی را مختل میکنند.

عواقب SPOF از دست رفتن اعتماد و هزینههای گزاف
🔍 مراحل شناسایی SPOF:
شناسایی SPOFها، اولین و حیاتیترین گام در استراتژی مقابله با آنهاست. این فرآیند باید به صورت مداوم و سیستماتیک انجام شود.
- تحلیل جامع سیستم (Comprehensive System Analysis):
- چه کاری انجام دهیم: تمام اجزای سیستم، از سختافزار (سرورها، روترها، سوئیچها، هارد دیسکها) و نرمافزار (سیستم عاملها، دیتابیسها، برنامههای کاربردی) تا زیرساخت شبکه و حتی فرآیندهای انسانی (مانند یک فرد کلیدی که تنها او دانش خاصی را دارد)، باید به دقت بررسی شوند.
- چرا این کار انجام میشود: برای ایجاد یک نقشه کامل از وابستگیها (Dependencies). اگر جزء A از جزء B برای عملکردش وابسته است، B یک کاندید SPOF است.
- چطور کار میکند: از نمودارهای معماری (Architecture Diagrams)، مستندات فنی و مصاحبه با تیمهای مختلف برای درک جریان دادهها و وابستگیها استفاده میشود.
- نظارت مستمر بر عملکرد (Continuous Performance Monitoring):
- چه کاری انجام دهیم: از ابزارهای نظارتی (Monitoring Tools) برای جمعآوری دادهها در مورد عملکرد، ظرفیت و وضعیت سلامت تمام اجزای سیستم استفاده کنید.
- چرا این کار انجام میشود: نقاطی که بیشترین بار (Load) را تحمل میکنند، یا مستعد خطاهای مکرر هستند، یا منابعشان (CPU, RAM, Disk I/O) به طور مداوم در آستانه اشباع قرار دارند، کاندیدای قوی برای SPOF هستند.
- چطور کار میکند: ابزارهایی مانند Prometheus, Grafana, Zabbix یا SolarWinds میتوانند به طور مداوم سلامت اجزا را رصد کرده و در صورت مشاهده الگوهای غیرعادی، هشدار دهند. این هشدارها باید به طور فعال توسط تیمهای عملیاتی بررسی شوند.
- مدیریت ریسک و اولویتبندی (Risk Management & Prioritization):
- چه کاری انجام دهیم: تأثیرات احتمالی خرابی هر SPOF شناسایی شده را از نظر مالی، عملیاتی، امنیتی و اعتباری ارزیابی کنید.
- چرا این کار انجام میشود: با توجه به منابع محدود، نمیتوان تمام SPOFها را همزمان رفع کرد. باید SPOFهایی که بیشترین ریسک و تأثیر منفی را دارند، در اولویت قرار گیرند.
- چطور کار میکند: از ماتریس ریسک (Risk Matrix) برای طبقهبندی SPOFها بر اساس احتمال وقوع (Likelihood) و شدت تأثیر (Impact) استفاده میشود.
مراحل شناسایی SPOF
🛡️ روشهای مقابله با SPOF:
پس از شناسایی، مرحله بعدی حذف یا کاهش SPOFهاست. این کار از طریق استراتژیهای زیر انجام میشود:
🚀 ۱. افزونگی (Redundancy)
Redundancy به معنای فراهم کردن اجزا، مسیرها یا سیستمهای جایگزین برای هر جزء حیاتی است. اگر جزء اصلی از کار افتاد، جزء پشتیبان فوراً وارد عمل میشود.
- چرا انجام میشود: ایجاد ظرفیت اضافی برای تحمل خرابی (Fault Tolerance).
- چطور کار میکند:
- سختافزاری:
- سرورهای پشتیبان (Redundant Servers): استفاده از چندین سرور (به جای یک سرور) در یک کلاستر (Cluster) یا دیتاسنتر. اگر یکی از کار بیفتد، دیگری ادامه میدهد.
- RAID (Redundant Array of Independent Disks): ترکیب چندین هارد دیسک برای افزایش عملکرد و/یا محافظت از دادهها. اگر یک دیسک خراب شود، دادهها از دیسکهای دیگر قابل بازیابی هستند.
- منابع تغذیه دوگانه (Dual Power Supplies): برای سرورها و تجهیزات شبکه حیاتی.
- شبکهای:
- مسیرهای شبکه جایگزین (Alternate Network Paths): استفاده از چندین روتر، سوئیچ و خطوط اینترنت مجزا (Dual ISP) برای جلوگیری از قطعی شبکه.
- HSRP/VRRP (Hot Standby Router Protocol/Virtual Router Redundancy Protocol): ایجاد روترهای پشتیبان برای درگاههای پیشفرض.
- جغرافیایی: میزبانی کپیهایی از سیستم در دیتاسنترهای مختلف یا مناطق جغرافیایی دور از هم.
- سختافزاری:
⚖️ ۲. توزیع بار (Load Balancing)
Load Balancer ابزاری است که ترافیک ورودی را بین چندین سرور یا منبع توزیع میکند تا از بارگذاری بیش از حد یک سرور جلوگیری کرده و در عین حال، عملکرد را بهبود بخشد.
- چرا انجام میشود: افزایش ظرفیت پردازش، بهبود پاسخگویی و ایجاد Redundancy. اگر یکی از سرورها از کار بیفتد، Load Balancer به طور خودکار ترافیک را به سرورهای سالم هدایت میکند.
- چطور کار میکند:
- DNS Load Balancing: ترافیک را بین چندین آدرس IP یک دامنه توزیع میکند.
- Hardware Load Balancers: دستگاههای فیزیکی مانند F5 BIG-IP.
- Software Load Balancers: راهحلهای نرمافزاری مانند Nginx، HAProxy، یا Load Balancerهای ابری (AWS ELB, Azure Load Balancer).
💾 ۳. پشتیبانگیری و بازیابی (Backup & Recovery)
تهیه نسخههای پشتیبان منظم از دادهها و سیستمها، و داشتن یک برنامه بازیابی فاجعه (Disaster Recovery Plan)، آخرین خط دفاعی در برابر SPOF است.
- چرا انجام میشود: در صورت بروز فاجعه یا از دست رفتن دادهها به دلیل خرابی SPOF، امکان بازگشت سریع به حالت عادی را فراهم میکند.
- چطور کار میکند:
- پشتیبانگیری منظم: از تمام دادهها، پیکربندیها و سیستم عاملها.
- ذخیرهسازی خارج از سایت (Off-site Storage): نگهداری نسخههای پشتیبان در مکانی جداگانه از سیستم اصلی.
- تست دورهای بازیابی: اطمینان از اینکه نسخههای پشتیبان سالم هستند و میتوانند با موفقیت بازیابی شوند.
- Recovery Point Objective (RPO) و Recovery Time Objective (RTO): تعریف اهداف مشخص برای میزان از دست رفتن داده و زمان بازیابی سرویس.
📈 ۴. طراحی سیستمهای مقیاسپذیر (Scalable System Design)
سیستمهای مقیاسپذیر به گونهای طراحی میشوند که بتوانند با افزودن منابع جدید (مانند سرورهای بیشتر) به راحتی ظرفیت خود را افزایش دهند. این قابلیت، به طور طبیعی، SPOFها را کاهش میدهد.
- چرا انجام میشود: به جای تکیه بر یک جزء واحد و قدرتمند (Scale Up)، از چندین جزء کوچکتر و قابل افزایش (Scale Out) استفاده میکند.
- چطور کار میکند:
- معماری میکروسرویس (Microservices Architecture): تقسیم یک برنامه بزرگ به سرویسهای کوچک و مستقل که میتوانند به صورت جداگانه توسعه و مقیاسپذیری داشته باشند.
- کانتینرسازی و ارکستراسیون (Containers & Orchestration): استفاده از Docker و Kubernetes برای مدیریت و مقیاسپذیری برنامهها.
- زیرساخت ابری (Cloud Infrastructure): قابلیت مقیاسپذیری خودکار منابع (Auto-Scaling) در پلتفرمهای ابری.
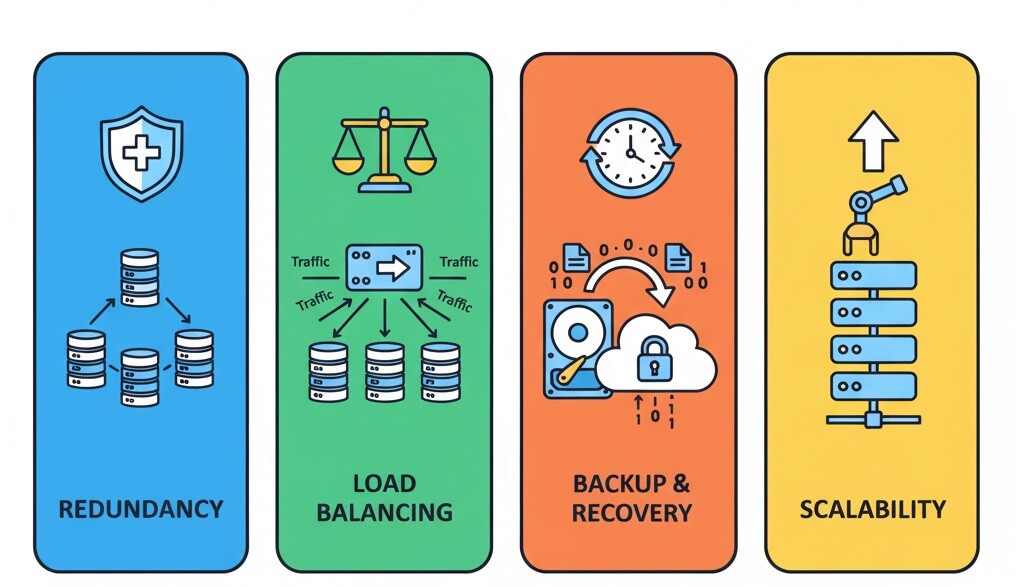
اینفوگرافی استراتژی های مقابله با SPOF
💡 برای نمونه: یک مشتری زویپ سرور، با یک پلتفرم تجارت الکترونیک (e-commerce) بزرگ، نیاز به Uptime نزدیک به 100% داشت. هر دقیقه قطعی میتوانست به معنای از دست دادن میلیاردها تومان فروش باشد. طراحی اولیه آنها دارای یک SPOF در دیتابیس بود.
راهحل: برای این مشتری، راهحلی بر پایه Redundancy و Load Balancing پیادهسازی کرد:
- سرورهای وب Redundant: چندین سرور VPS قدرتمند اوبونتو برای وبسرورها، پشت یک Load Balancer قرار گرفتند.
- دیتابیس HA: از یک دیتابیس کلاستر (مانلاً MariaDB Galera Cluster) با سه گره (Node) استفاده شد تا در صورت خرابی یک گره، دیتابیس به کار خود ادامه دهد.
- فضای ذخیرهسازی Redundant: از فضای ذخیرهسازی ابری با قابلیت Replication استفاده شد.
- مانیتورینگ پیشرفته: ابزارهای مانیتورینگ 24/7 برای تشخیص زودهنگام هرگونه مشکل احتمالی.
نتایج:
- Uptime بالای 99.99%: پلتفرم e-commerce حتی در صورت بروز مشکل در یک سرور یا دیتابیس، به کار خود ادامه داد.
- عملکرد بهینه: Load Balancer ترافیک را به طور هوشمند توزیع کرد و بهینهترین عملکرد را تضمین نمود.
- اعتماد مشتری: مشتری از پایداری سرویس خود رضایت کامل داشت و از از دست رفتن فروش جلوگیری شد.

🧰 عیبیابی SPOF
تشخیص SPOF بعد از وقوع فاجعه معمولاً آسان است، اما تشخیص پیشگیرانه آن هنر است.
- ⛔️ مشکل: سیستم به طور مکرر و غیرقابل پیشبینی از کار میافتد.
- راهحل: نقشههای وابستگی سیستم را بازبینی کنید. از ابزارهای مانیتورینگ برای شناسایی اجزایی که در زمان خرابی تحت بار شدید یا دارای خطا هستند، استفاده کنید. ممکن است یک سرویس پنهان وجود داشته باشد که همه چیز به آن وابسته است.
- ❌ مشکل: یک جزء (مثلاً یک دیتابیس) همیشه تحت بار بسیار بالا قرار دارد.
- راهحل: این یک SPOF بالقوه است. به فکر مقیاسپذیری آن جزء (Scale Out) یا استفاده از راهحلهای Redundant برای آن باشید. Load Balancerها نیز میتوانند کمککننده باشند.
📌 نکته: فقط به جنبههای فنی محدود نشوید. “دانش یک فرد کلیدی” (Key Person Dependency) نیز میتواند یک SPOF باشد. مستندسازی قوی و آموزش cross-functional (آموزش دادن مهارتهای یک تیم به تیمهای دیگر) برای کاهش این ریسک حیاتی است.
سؤال: آیا تا به حال SPOF پنهانی در سیستمهای خود کشف کردهاید که شما را غافلگیر کرده باشد؟ تجربه خود را با ما در میان بگذارید!
🧐 پرسشهای متداول (FAQ) در مورد SPOF
- 🔹 آیا میتوان تمام SPOFها را از یک سیستم حذف کرد؟
- به صورت تئوری بله، اما در عمل و با توجه به محدودیتهای بودجه و پیچیدگی، حذف تمام SPOFها بسیار دشوار و پرهزینه است. هدف، کاهش و مدیریت SPOFهای بحرانی برای دستیابی به سطح بالایی از High Availability است.
- 🚀 تفاوت Redundancy و High Availability چیست؟
- Redundancy (افزونگی) به معنای داشتن اجزای جایگزین است. High Availability (HA) (دسترسیپذیری بالا) نتیجه پیادهسازی مؤثر Redundancy و سایر استراتژیها برای اطمینان از این است که سیستم برای مدت طولانی در دسترس است. Redundancy یک ابزار است؛ HA یک هدف.
- ⚠️ چه نوع SPOFهایی اغلب نادیده گرفته میشوند؟
- تکنقطه شبکه (Single Network Uplink): فقط یک کابل یا یک ISP.
- یک دیتابیس منفرد (Single Database Instance): بدون Replication یا Clustering.
- دانش یک فرد خاص (Key Person Dependency): فقط یک نفر میداند چگونه یک سیستم خاص را مدیریت کند.
- سیستمهای قدیمی (Legacy Systems): که بهروزرسانی یا Redundant کردن آنها دشوار است.
- 🛡️ چگونه میتوانم از شرکت میزبان (Hosting Provider) در مورد SPOFها سوال کنم؟
- از آنها در مورد معماری دیتاسنتر (Dual Power, Redundant Network), SLA، نحوه مدیریت سختافزارهای Failover (مثل RAID)، و گزینههای HA برای سرویسهای خود (مثل Load Balancer, Managed Databases) بپرسید.
🎉 نتیجهگیری:
SPOF (Single Point of Failure) یک چالش پنهان اما حیاتی در هر سیستم دیجیتال است. نادیده گرفتن آن میتواند به فجایع پرهزینه و از دست رفتن اعتماد منجر شود. اما با درک صحیح این مفهوم، شناسایی دقیق SPOFها و پیادهسازی استراتژیهای هوشمندانه مانند Redundancy، Load Balancing، Backup و طراحی مقیاسپذیر، میتوانیم سیستمهایی بسازیم که نه تنها قدرتمند، بلکه انعطافپذیر و مقاوم در برابر هر گونه شکست باشند.
زویپ سرور با ارائه انواع خدمات هاست، سرور مجازی و اختصاصی، دامنه و لایسنس، همراه شما در این مسیر هست. اگه قصد راهاندازی هاستینگ خودتون رو دارید یا به منابع قویتری نیاز دارید، خرید سرور مجازی و لایسنس سی پنل از زویپ سرور میتونه یک انتخاب هوشمندانه باشه. تیم متخصص زویپ سرور آمادهی نصب و کانفیگ کامل سرور برای شماست تا با خیال راحت روی کسبوکارتون تمرکز کنید.
سرورهای مجازی ایران زویپ سرور:
- سرور مجازی ایران – دیتاسنتر پارسیان (NVMe)
- سرور مجازی ایران – نامحدود (NVMe)
- سرور مجازی ایران – دیتاسنتر امین (NVMe)
مشاهده پلنهای سرورهای مجازی خارج زویپ سرور:
- مشاهده پلنهای سرورهای (NVMe) OVH
- مشاهده پلنهای سرورهای هتزنر (NVMe)
- مشاهده پلنهای سرورهای کلوکراسینگ (NVMe)
منابع:
[1] identifying and eliminating network single points of failure spof.
[2] Open Shortest Path First (OSPF) Protocol States.
[4] What is OSPF?
[5] Single Point of Failure (SPOF): How to Identify and Eliminate It?
[6] How to Avoid Single Point of Failures?
[7] cloudflare what-is-load-balancing




