
سرورهای High Availability (HA)، یکی از کلیدیترین فناوریها در دنیای امروز بهخصوص در سازمانها و مراکز داده هستند. هدف اصلی این فناوری، تضمین دسترسی مستمر و بدون وقفه به سرویسها و اپلیکیشنها در طول زمان است. در دنیای دیجیتال امروزی، که بسیاری از خدمات آنلاین، سیستمهای بانکی، تجارت الکترونیک و سرویسهای ابری به طور ۲۴ ساعته در حال اجرا هستند، هیچچیز به اندازه از دست دادن دسترسی به یک سرویس حیاتی، آسیبزا و پرهزینه نیست.
High Availability به معنای افزایش قابلیت اطمینان سیستمها و سرویسها با استفاده از روشهایی است که باعث میشود حتی در صورت بروز مشکلات سختافزاری، نرمافزاری یا شبکهای، سرویسها همچنان در دسترس باقی بمانند. در واقع، HA تضمین میکند که سرویسها به صورت مداوم، حتی در شرایط بحرانی، به کار خود ادامه دهند.
در این مقاله، ما به بررسی دقیق مفهوم، پیادهسازی و پیکربندی سرورهای High Availability خواهیم پرداخت. هدف اصلی ما این است که به شما کمک کنیم تا با مفاهیم و بهترین شیوههای پیادهسازی این فناوری آشنا شوید و بتوانید سرورهای HA را در محیطهای مختلف راهاندازی و مدیریت کنید.
این مقاله، برای کسانی که به دنبال درک دقیقتری از پیکربندی سرورهای HA و مدیریت بار کاری (Load Balancing) هستند، مناسب است. همچنین در اینجا به بررسی ابزارها و تکنیکهایی خواهیم پرداخت که در پیادهسازی HA نقش اساسی دارند.
ضرورت High Availability در دنیای امروز
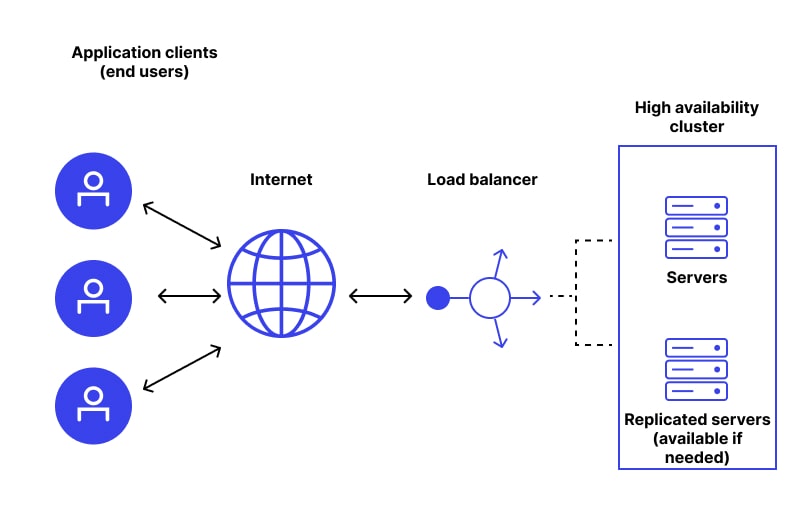
امروزه، بیشتر کسبوکارها و خدمات آنلاین در معرض خطرات و تهدیدات زیادی قرار دارند که میتواند موجب بروز اختلالات در سرویسها و از دست دادن دادهها شود. از این رو، داشتن یک معماری HA میتواند برای سازمانها و شرکتها حائز اهمیت باشد. از دیگر دلایل نیاز به HA میتوان به موارد زیر اشاره کرد:
- تداوم خدمات و کاهش زمان توقف: استفاده از سرورهای HA باعث میشود که خدمات در صورت بروز خطا یا خرابی، بدون وقفه ادامه یابند.
- کاهش خسارات مالی: هرچه زمان توقف سرویسها کوتاهتر باشد، خسارات مالی ناشی از این توقفها نیز کاهش مییابد.
- بهبود تجربه کاربری: کاربران و مشتریان به خدماتی که در دسترس باشند اعتماد بیشتری دارند، که این امر بر وفاداری مشتریان تأثیر مثبت میگذارد.
- مقیاسپذیری و انعطافپذیری: سرورهای HA این امکان را فراهم میکنند که زیرساختها به راحتی برای پاسخ به تقاضاهای بیشتر مقیاسپذیر شوند.
مفاهیم پایهای High Availability
قبل از هر چیز، باید بدانیم که High Availability چیست و چه ویژگیهایی آن را از سایر روشهای ارائه سرویسها متمایز میکند. در این بخش، به توضیح مفاهیم پایهای HA، انواع مختلف آن و معیارهای ارزیابی آن خواهیم پرداخت.
1. تعریف High Availability و تفاوت با Fault Tolerance
High Availability به معنای افزایش دسترسی و عملکرد سرویسها در شرایط بحرانی است. هدف اصلی آن این است که سرویسها و سیستمها حتی در صورت بروز مشکلاتی مانند خرابی سختافزاری، خطاهای نرمافزاری یا قطعیهای شبکهای همچنان در دسترس باقی بمانند.
در مقابل، Fault Tolerance به معنای توانایی یک سیستم در برابر خطاها است. سیستمهای Fault Tolerant به گونهای طراحی میشوند که حتی در صورت بروز خطا در بخشهایی از سیستم، عملکرد کلی سیستم حفظ شود.
به طور کلی، High Availability به مدیریت زمان در دسترس بودن (Uptime) سیستمها میپردازد، در حالی که Fault Tolerance بیشتر به توانایی سیستم در تحمل خطا و ادامه عملکرد تحت شرایط بحرانی اشاره دارد.
2. معیارهای High Availability
برای ارزیابی موفقیت در پیادهسازی HA، نیاز است تا برخی از معیارهای کلیدی را در نظر بگیریم:
- Uptime (زمان در دسترس بودن): بالاترین معیار در HA، میزان زمانی است که یک سیستم به طور کامل در دسترس است. هرچه این عدد بیشتر باشد، سیستم قابلیت اعتماد بیشتری دارد.
- MTTR (Mean Time to Repair): میانگین زمان لازم برای تعمیر و بازیابی سیستم پس از وقوع خرابی.
- MTBF (Mean Time Between Failures): میانگین زمان بین دو خرابی متوالی در سیستم.
- RPO (Recovery Point Objective) و RTO (Recovery Time Objective): این دو معیار به ترتیب نشاندهنده حداکثر زمان قابل قبول برای از دست رفتن دادهها و حداکثر زمان لازم برای بازیابی سیستم پس از وقوع خرابی هستند.
این معیارها معمولاً به عنوان SLA (Service Level Agreement) در قراردادهای تجاری تعیین میشوند و برای هر سازمان یا سرویس ممکن است متفاوت باشند.
3. انواع معماریهای High Availability
معماریهای مختلفی برای پیادهسازی HA وجود دارند که بسته به نیازها و شرایط خاص هر سازمان، انتخاب میشوند. دو نوع رایج معماریهای HA عبارتند از:
- Active/Passive: در این نوع معماری، یک سرور فعال وجود دارد که درخواستها را پردازش میکند و یک سرور پشتیبان (Passive) که در حالت آماده به کار است. اگر سرور اصلی دچار خرابی شود، سرور پشتیبان به طور خودکار جایگزین آن میشود و شروع به ارائه خدمات میکند.
- Active/Active: در این نوع معماری، چندین سرور به طور همزمان در حال پردازش درخواستها هستند. در صورت بروز خرابی در یکی از سرورها، بقیه سرورها همچنان ادامه میدهند و هیچ قطعی در سرویس مشاهده نمیشود.
4. Load Balancing و Failover
در هر سیستم HA، یکی از تکنیکهای اصلی برای دستیابی به پایداری و مقیاسپذیری، استفاده از Load Balancer و Failover است.
- Load Balancing: به فرآیند توزیع بار کاری (درخواستها) میان چندین سرور گفته میشود. این کار باعث میشود که هیچ یک از سرورها بیش از حد بارگذاری نشود و کارایی سیستم حفظ شود.
- Failover: این مکانیزم به سیستم این امکان را میدهد که در صورت بروز خرابی در یکی از بخشهای آن، به طور خودکار به یک سیستم یا سرویس پشتیبان منتقل شود. این عمل معمولاً در صورت خرابی سرور، دیتابیس یا شبکه انجام میشود.
5. Redundancy (واحدهای پشتیبان)
برای تحقق HA، نیاز است که واحدهای پشتیبان در سطحهای مختلف (سختافزار، شبکه، داده و …) در نظر گرفته شوند. به عبارت دیگر، هر جزء سیستم باید به گونهای طراحی شود که در صورت خرابی، سیستم به سرعت بتواند به منابع پشتیبان منتقل شود.
این فرآیند به صورت Redundancy یا پشتیبانسازی افزایشی شناخته میشود و معمولاً شامل موارد زیر میشود:
- Redundant Power Supplies: سیستمهایی که منبع تغذیه اضافی دارند تا در صورت بروز خرابی در منبع اصلی، سیستم همچنان فعال باشد.
- Redundant Network Connections: ارتباطات شبکهای اضافی برای جلوگیری از قطعیهای شبکه.
- Redundant Storage Systems: ذخیرهسازی دادهها به صورت افزایشی (RAID یا سیستمهای مشابه) برای جلوگیری از از دست دادن دادهها.
6. Clustering و Cluster-aware Software
Clustering به فرآیند گروهبندی چندین سرور گفته میشود که به طور همزمان در حال پردازش درخواستها هستند و به عنوان یک سیستم واحد عمل میکنند. نرمافزارهای مخصوص Cluster-aware برای اطمینان از هماهنگی بین این سرورها طراحی شدهاند و معمولاً در زمینه دیتابیسها و سرویسهای پردازشی مانند MySQL Cluster یا Oracle RAC مورد استفاده قرار میگیرند.
اجزای تشکیلدهنده سرورهای High Availability
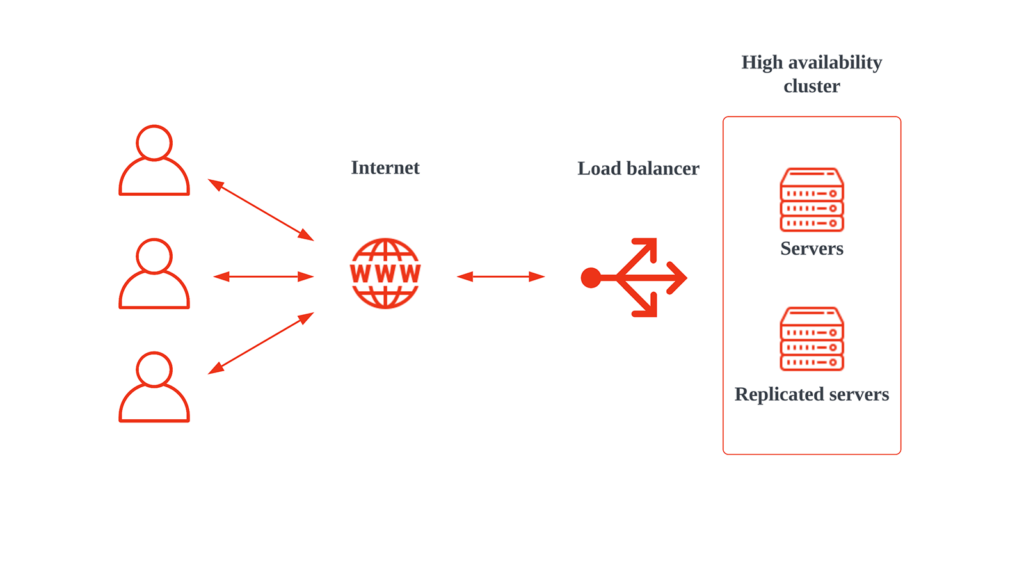
برای پیادهسازی یک سیستم High Availability موفق، نیاز به یک زیرساخت کامل و چندین جزء حیاتی است. این اجزا شامل سختافزار، نرمافزارهای مدیریتی، سیستمهای ذخیرهسازی و شبکههای ارتباطی هستند که باید با هم بهطور هماهنگ عمل کنند تا به بالا بردن دسترسپذیری و پایداری سیستم کمک کنند.
1. سختافزارهای ضروری برای پیادهسازی HA
- سرورهای فیزیکی یا مجازی:
- سرورهای فیزیکی و مجازی میتوانند به عنوان بخش اصلی در پیادهسازی HA عمل کنند. سرورهای فیزیکی معمولاً برای سازمانهای بزرگتر که نیاز به مقیاسپذیری بسیار بالا دارند، مناسب هستند. اما برای سازمانهای کوچکتر یا محیطهای آزمایشی، استفاده از سرورهای مجازی میتواند مقرون به صرفهتر و انعطافپذیرتر باشد.
- سرورهای HA معمولاً به صورت Redundant یا افزایشی پیادهسازی میشوند. یعنی در صورت بروز خرابی در یک سرور، یک سرور پشتیبان به سرعت جایگزین آن میشود.
- منابع تغذیه اضافی:
- یکی از اجزای حیاتی در معماری HA، منابع تغذیه افزایشی است. این به این معنی است که سرورها باید حداقل دو منبع تغذیه مستقل داشته باشند تا در صورت خرابی یک منبع، سرور همچنان فعال باقی بماند.
- هارد دیسکهای افزایشی و ذخیرهسازی:
- برای جلوگیری از از دست رفتن دادهها و افزایش در دسترس بودن، نیاز به سیستمهای ذخیرهسازی افزایشی (Redundant Storage) مانند RAID (Redundant Array of Independent Disks) داریم. این سیستمها از دادهها در چندین هارد دیسک پشتیبانگیری میکنند تا در صورت خرابی یک هارد، دادهها از هاردهای دیگر قابل بازیابی باشند.
2. نرمافزارهای مدیریت HA
نرمافزارهای مخصوص مدیریت و هماهنگی سیستمهای HA نقش حیاتی در مدیریت این سیستمها دارند. این نرمافزارها به طور معمول وظایفی مانند فیلتر کردن درخواستها، مدیریت بار کاری، و انتقال خودکار به سرورهای پشتیبان را انجام میدهند. برخی از نرمافزارهای مهم در این زمینه عبارتند از:
- Pacemaker:
- Pacemaker یکی از محبوبترین نرمافزارها برای پیادهسازی و مدیریت Clustering در محیطهای HA است. این نرمافزار وظیفه مدیریت Failover و Load Balancing را به عهده دارد و میتواند در صورت بروز خطا در یک سرور، به طور خودکار سرویسها را به سرورهای پشتیبان منتقل کند.
- Corosync:
- این نرمافزار به عنوان یک ابزار پیوند شبکهای برای هماهنگی بین نودهای مختلف در یک خوشه (Cluster) عمل میکند. Corosync معمولاً به عنوان یک جزء اصلی در کنار Pacemaker برای مدیریت ارتباطات بین نودهای HA استفاده میشود.
- Keepalived:
- Keepalived یکی از نرمافزارهای رایج برای Load Balancing و Failover است. این نرمافزار به صورت معمول برای پیکربندی Virtual IP Addresses و مدیریت VRRP (Virtual Router Redundancy Protocol) به کار میرود.
- HAProxy و Nginx:
- این دو نرمافزار به عنوان Load Balancer برای مدیریت توزیع بار بین سرورهای مختلف استفاده میشوند. HAProxy بهویژه در معماریهای Active/Active کاربرد زیادی دارد و میتواند درخواستها را بین چندین سرور به طور موثر توزیع کند.
3. سیستمهای ذخیرهسازی و دیتابیسهای HA
سیستمهای ذخیرهسازی افزایشی (Redundant Storage Systems) برای سیستمهای HA ضروری هستند. در صورتی که دادهها در یک نقطه مرکزی ذخیره شوند، احتمال از دست رفتن دادهها در صورت خرابی سرور افزایش مییابد. بنابراین، برای اطمینان از دسترسپذیری بالا و بازیابی سریع دادهها، از سیستمهای ذخیرهسازی با قابلیت افزایشی استفاده میشود. برخی از این سیستمها عبارتند از:
- RAID (Redundant Array of Independent Disks):
- یکی از رایجترین روشها برای ذخیرهسازی افزایشی است که به وسیله آن میتوان دادهها را در چندین دیسک ذخیره کرد. بسته به نوع RAID انتخابی (RAID 1، RAID 5 و …)، میزان افزایشی بودن و قابلیت بازیابی دادهها متفاوت است.
- DRBD (Distributed Replicated Block Device):
- این ابزار برای تکرار دادهها در سطح بلاک بین دو سرور استفاده میشود. به این ترتیب، میتوان دادهها را به صورت بلادرنگ در سرورهای مختلف ذخیره کرده و در صورت خرابی یکی از سرورها، سرور پشتیبان از دادههای جدید استفاده کند.
- Clustered File Systems (مانند GFS2 و OCFS2):
- این سیستمها به چندین سرور امکان میدهند که بهطور همزمان به یک سیستم فایل دسترسی داشته باشند. این ویژگی برای حفظ دادهها در محیطهای HA و جلوگیری از دست رفتن اطلاعات ضروری است.
4. شبکههای ارتباطی در HA
شبکههای ارتباطی در معماریهای HA نقش بسیار مهمی در حفظ ارتباطات مداوم بین سرورها، دیتابیسها و ذخیرهسازیها دارند. شبکههای مورد استفاده در این محیطها باید بسیار پایدار و با ظرفیت بالا باشند. برای اطمینان از ارتباط مستمر، موارد زیر باید در نظر گرفته شوند:
- شبکههای شبکههای افزایشی (Redundant Networking):
- برای جلوگیری از از دست رفتن ارتباطات شبکهای، باید از شبکههای پشتیبان برای هر نود استفاده کرد. این کار باعث میشود که در صورت خرابی یک اتصال شبکه، اتصال جایگزین به طور خودکار فعال شود.
- Load Balancers برای مدیریت بار شبکهای:
- Load Balancers نقش حیاتی در توزیع درخواستهای ورودی بین سرورها دارند و باعث میشوند که هیچ یک از سرورها به طور غیرضروری بارگذاری نشود. این کار علاوه بر بهبود عملکرد، باعث میشود که در صورت بروز خرابی در یکی از سرورها، بار به سرورهای سالم منتقل شود.
5. نرمافزارهای مانیتورینگ و مدیریت
نرمافزارهای مانیتورینگ برای پیگیری عملکرد سیستمهای HA ضروری هستند. این ابزارها به مدیران سیستمها کمک میکنند تا وضعیت سرورها و سرویسها را بررسی کرده و از بروز مشکلات قبل از وقوع آنها پیشگیری کنند. برخی از ابزارهای مانیتورینگ شامل:
- Zabbix:
- Zabbix یکی از ابزارهای محبوب برای مانیتورینگ سیستمها است. این نرمافزار قادر است وضعیت سرورها، شبکهها و نرمافزارهای HA را بررسی کرده و در صورت بروز مشکل، هشدارهای لازم را ارسال کند.
- Nagios:
- Nagios نیز به عنوان یک ابزار مانیتورینگ شناخته میشود که قابلیت پیگیری سلامت سیستمها و سرویسها را دارد.
پیادهسازی و پیکربندی سرورهای High Availability
در این بخش، به بررسی مراحل گام به گام برای پیادهسازی یک سیستم High Availability خواهیم پرداخت. برای سادهسازی این فرآیند، یک معماری Active/Passive را بهعنوان نمونه در نظر میگیریم. در این معماری، یک سرور فعال بهطور معمول سرویسها را ارائه میدهد، و یک سرور پشتیبان (Passive) در حالت آمادهبهکار است. در صورت خرابی سرور فعال، سرور پشتیبان بهطور خودکار جایگزین آن میشود.
1. انتخاب و نصب سیستمعامل
اولین گام در پیادهسازی یک سرور HA، انتخاب و نصب سیستمعامل مناسب است. برای این منظور، معمولاً از سیستمعاملهای لینوکسی مانند Ubuntu Server، CentOS یا Red Hat Enterprise Linux (RHEL) استفاده میشود. این سیستمعاملها ابزارهای لازم برای پیادهسازی و پیکربندی HA را بهطور پیشفرض فراهم میکنند.
برای مثال، در اینجا از Ubuntu Server استفاده میکنیم:
- نصب Ubuntu Server: ابتدا سیستمعامل را بر روی هر دو سرور (Active و Passive) نصب کنید. در نصب، گزینههایی مانند OpenSSH Server را برای دسترسی به سرور از راه دور انتخاب کنید.
2. نصب و پیکربندی Pacemaker و Corosync
یکی از مهمترین ابزارهایی که در پیادهسازی HA در لینوکس استفاده میشود، Pacemaker و Corosync هستند. Corosync مسئول فراهم کردن ارتباطات بین نودهای مختلف (سرورها) است، در حالی که Pacemaker مسئول مدیریت منابع و انتقال خودکار سرویسها به سرورهای پشتیبان در صورت خرابی است.
برای نصب این ابزارها بر روی هر دو سرور، میتوانید از دستورهای زیر استفاده کنید:
sudo apt update sudo apt install pacemaker corosync- پیکربندی Corosync: Corosync باید بهطور صحیح پیکربندی شود تا ارتباطات میان سرورهای مختلف برقرار باشد. فایل پیکربندی آن معمولاً در مسیر /etc/corosync/corosync.conf قرار دارد. در این فایل، باید آدرسهای IP سرورهای مختلف در خوشه (Cluster) را وارد کنید.
- پیکربندی Pacemaker: پس از نصب، باید Pacemaker را برای مدیریت منابع پیکربندی کنید. از دستور زیر برای شروع Pacemaker و ایجاد یک خوشه (Cluster) استفاده کنید:
sudo systemctl start pacemaker sudo systemctl enable pacemaker3. پیکربندی Virtual IP (VIP) برای HA
در معماریهای Active/Passive، معمولاً از یک آدرس IP مجازی (VIP) استفاده میشود که درخواستها به آن آدرس هدایت میشود. این IP به طور خودکار بین سرور فعال و پشتیبان منتقل میشود. برای پیکربندی VIP، باید از ابزارهایی مانند Keepalived یا Pacemaker استفاده کنید.
برای نصب و پیکربندی VIP با Pacemaker، مراحل زیر را دنبال کنید:
- ایجاد Resource برای VIP:
sudo crm configure primitive VIP ocf:heartbeat:IPaddr2 params ip=192.168.1.100 cidr_netmask=24 op monitor interval=10sدر این دستور، 192.168.1.100 به عنوان آدرس IP مجازی تنظیم شده است.
- پیکربندی Failover برای VIP:
sudo crm configure colocation vip_with_node inf: VIP node1 sudo crm configure order vip_after_node 0: VIP start node1این پیکربندی باعث میشود که VIP ابتدا به سرور فعال (node1) اختصاص داده شود و در صورت خرابی، به سرور پشتیبان منتقل شود.
4. نصب و پیکربندی Load Balancer
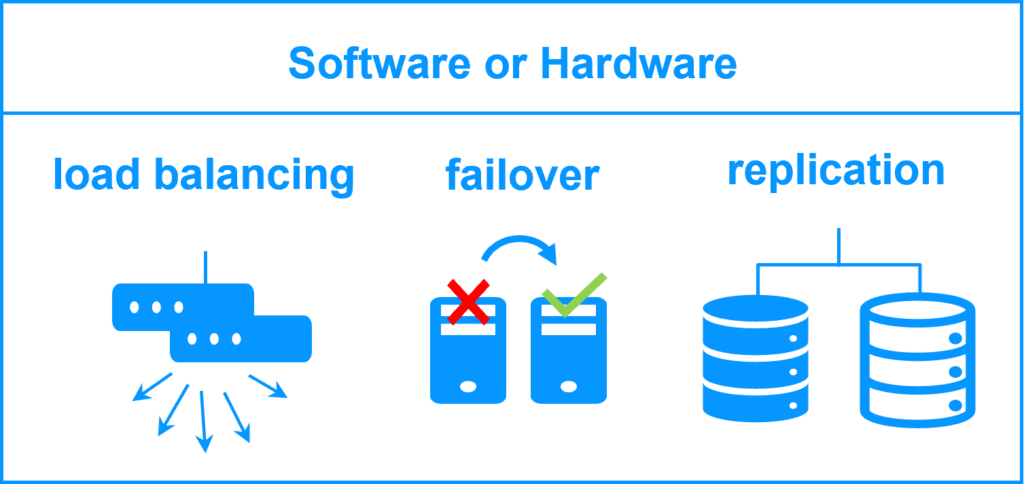
برای دستیابی به بارگذاری متوازن (Load Balancing) در محیطهای HA، باید از ابزارهایی مانند HAProxy یا Nginx استفاده کنید. این ابزارها به شما کمک میکنند که درخواستها را بین سرورهای مختلف توزیع کرده و بهطور مداوم در دسترس باشند.
- نصب HAProxy:
sudo apt install haproxy- پیکربندی HAProxy:
برای پیکربندی HAProxy، باید فایل تنظیمات آن را ویرایش کنید. در فایل /etc/haproxy/haproxy.cfg میتوانید تنظیمات زیر را برای بارگذاری متوازن سرورها اضافه کنید:
frontend http_front bind *:80 default_backend http_back backend http_back balance roundrobin server server1 192.168.1.101:80 check server server2 192.168.1.102:80 checkاین تنظیمات باعث میشود که درخواستها بهطور متوازن بین دو سرور 192.168.1.101 و 192.168.1.102 توزیع شوند.
5. پیادهسازی Storage Redundancy
برای اطمینان از در دسترس بودن دادهها در صورت خرابی یک سرور، باید از سیستمهای ذخیرهسازی افزایشی (RAID) یا DRBD برای ذخیرهسازی دادهها استفاده کنید.
- راهاندازی RAID: بسته به نوع RAID که میخواهید استفاده کنید (مانند RAID 1 یا RAID 5)، میتوانید از دستور mdadm برای ایجاد آرایههای RAID استفاده کنید:
sudo mdadm --create /dev/md0 --raid-devices=2 /dev/sda /dev/sdbاین دستور یک آرایه RAID 1 بین دو دیسک /dev/sda و /dev/sdb ایجاد میکند.
- راهاندازی DRBD: برای نصب DRBD (برای همگامسازی دادهها بین دو سرور)، دستور زیر را اجرا کنید:
sudo apt install drbd-utilsسپس باید فایل پیکربندی /etc/drbd.conf را برای همگامسازی دادهها بین دو سرور پیکربندی کنید.
6. تست و نظارت بر HA
پس از پیکربندی همه اجزاء، باید سیستم را تست کنید تا اطمینان حاصل کنید که در صورت خرابی یکی از سرورها، سرویسها بهطور خودکار به سرور پشتیبان منتقل میشوند.
برای تست Failover، میتوانید سرور فعال را به صورت دستی خاموش کنید و بررسی کنید که آیا سرور پشتیبان بهطور خودکار جایگزین آن میشود یا خیر.
- نظارت با ابزارهای مدیریت: ابزارهایی مانند Zabbix یا Nagios میتوانند به شما کمک کنند تا سلامت و عملکرد سیستم HA خود را در طول زمان نظارت کنید.
جمعبندی
در این بخش، به بررسی گام به گام نحوه پیادهسازی و پیکربندی یک سیستم High Availability پرداختیم. مراحل شامل نصب سیستمعامل، نصب ابزارهای HA مانند Pacemaker و Corosync، پیکربندی Virtual IP (VIP)، و تنظیم بارگذاری متوازن با استفاده از HAProxy بود. همچنین به اهمیت استفاده از RAID یا DRBD برای اطمینان از دسترسپذیری دادهها اشاره کردیم.




